在Java的面试题中,JVM也经常会被问到,例如下面是一些经典的题目:
- 请你谈谈对JVM的理解?java8虚拟机和之前的变化是什么?
- 什么是OOM,什么是栈溢出StackOverFlowError,怎么分析?
- JVM的常用调优参数有哪些?
- 内存快照如何获取,怎么分析Dump文件?
- 谈谈JVM中的类加载器?
等等。其实这些问题在理解JVM后也都比较基础,那么就带着问题来揭开JVM的面纱吧。
JVM体系结构
正如下图所示,是一个很简单的结构图,没有把复杂的功能显示出来,而主要揭示了JVM的组成部分。
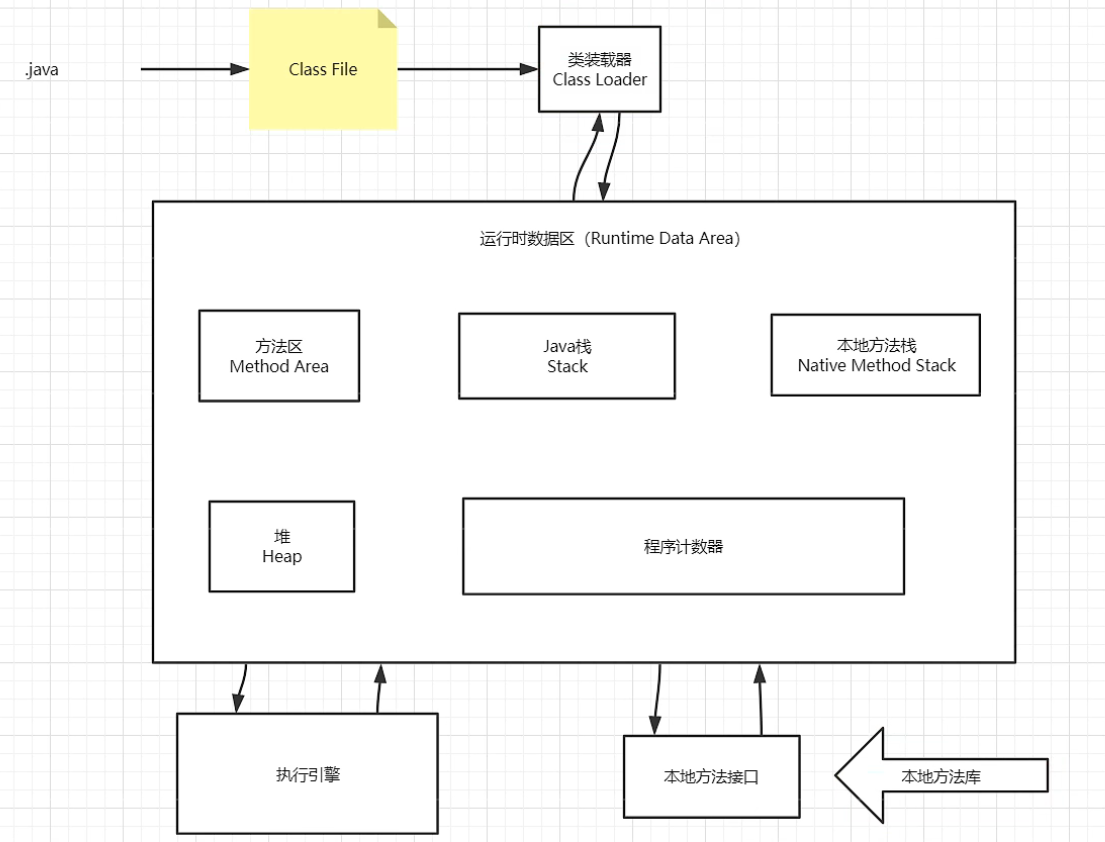
JVM本身位于操作系统之上,是用C++写的。目的是简化java语言,在jvm中隐蔽了指针概念,以及内存管理等功能。并基于垃圾回收(GC)机制来自动管理内存。Java栈、本地方法栈以及程序计数器中不可能产生“垃圾”,“垃圾”在方法区(特殊堆区)和堆区产生,故JVM的调优也主要是对堆的调优。
类加载器
来思考一个问题,new一个类的时候,java是怎么生成这个实例对象的呢?
这里以Car类为例:首先编写Car类的.java文件,通过javac编译为.class文件,然后由类加载器进行加载。
类加载器会为这个类构建一个模板类,然后由模板类去实例化对象,即在栈中存放对象引用,在堆中分配内存并初始化对象。整个过程如下图所示:

也可以写一段代码来验证这个过程:
1 | public class Car { |
其输出结果为:
1 | 2083562754 |
可以发现,两个car对象的hashcode不同,但是他们的类模板是同一个类—hashcode相同。
类加载器的功能可以总结如下:
- 防止恶意代码去干涉善意的代码; — 双亲委派机制
- 守护了被信任的类库边界;
- 将代码归入保护域(domain),确定了代码可以进行哪些操作。
双亲委派机制
其实,类加载器有很多种,可以在模板类上调用getClassLoader方法来获得类加载器。具体种类有:
- 启动类(根)加载器
- 扩展类加载器
- 应用程序加载器
双亲委派机制主要是为了保障安全。在类加载器收到加载类的请求后,会将该请求向上委托给父亲加载器(扩展加载器,根加载器)去完成,一直向上委托。启动加载器检查是否能够加载这个类,能加载就结束;否则抛出异常,通知子加载器进行加载。
这样能够保障java关键字的安全。例如,自己写一个java.lang包下的String类,那么会委托到根加载器(rt.jar)中加载String类,而不是应用程序加载器中自己写的String类。
在之前Car类的例子中,我们也可以查看加载Car的是哪个类加载器,然后还可以不断回溯上层的类加载器:
1 | // 类加载器 |
沙箱安全机制
沙箱(sandbox)其实就是限制程序运行的环境。该机制也是为了保障安全的。
java代码分为本地方法和远程方法,本地方法默认安全,但是远程方法不一定有安全机制后,本地/远程代码会按照用户的安全策略设定,由类加载器加载到虚拟机中权限不同的运行空间中,来实现差异化代码执行权限控制。
Native,方法区
还记得JVM结构中有本地方法接口、本地方法库和本地方法栈吧。那么什么是本地(Native)方法呢?来看下面这段代码:
1 | public class Main { |
是以Runnable接口启动一个线程的示例。深入start方法可以看到其内部含有native方法start0(),但是直接在类中像c函数声明一样写了,并没有方法体。而且若把native去掉,则是不合法的。
其实,带有native关键字,就表明java的作用范围达不到了,会去调用底层C语言的库!
而带有native关键字的方法,其实就是所谓的本地方法接口(JNI),它的目的是 扩展java的使用,融合不同的编程语言为java所用。使用native方法会进入本地方法栈,这是jvm在内存区域专门开辟的一块标记区域,用来登记native方法,并在执行引擎执行时加载本地方法库中的方法。
目前,JNI方法其实写的比较少,除非是控制硬件的场景,例如控制打印机、rdma的时候会有需要。
扩展:在java中调用其他接口,除了JNI还有很多其他方式,例如:socket,webservice,http等。
PC寄存器
程序计数器(Program Counter Register)
每个线程都有一个程序计数器,是线程私有的,就是一个指针,指向方法区中的方法字节码。在执行引擎中读取下一条指令,是一个非常小的内存空间,几乎可以忽略不计。
方法区
Method Area,方法区是被所有线程共享的。所有字段和方法字节码,以及一些特殊方法(构造函数,接口)也在此定义。
静态变量(static)、常量(final)、类信息(类模板)、运行时常量池都存在于方法区中,但是实例变量存在堆内存中,与方法区无关。
栈区
栈区还是比较好理解,其实就是FILO的栈数据结构,记住几个要点吧:
- 栈内存:是线程私有的,主管程序的运行,其生命周期和线程同步;
- 线程结束,其栈内存也就释放了,所以对于栈来说,也不存在垃圾回收;
- 栈中存放的内容:8大基本类型 + 对象引用 + 实例的方法;
- 栈运行的原理:栈帧(方法索引,输入输出参数,本地变量,Class File引用,父帧,子帧);
- 栈满了:抛出
StackOverflowError异常
下面再来说说,栈、堆还有方法区之间的一些联系和互动:

java利用类加载器创建类模板,并构建对象实例。在栈中生成对象引用,堆中为实例对象分配内存、赋值,其中的常量保存在方法区的常量池中。这便是其中的一些联系。
堆区
Heap,一个JVM只有一个堆内存,堆内存的大小是可以调节的。
类加载器读取了类文件后,一般会把哪些东西放到堆中呢?
类,方法,常量,变量,以及所有引用类型的真实对象。
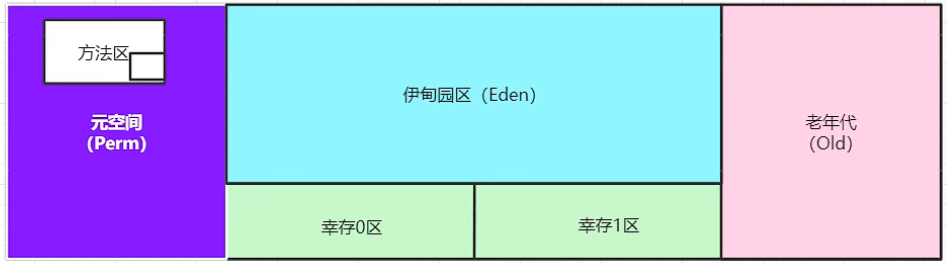
由于堆中会存在“垃圾”,为了更好地管理“垃圾”,堆空间需要进一步细分,具体可分为三个区域:
- 新生区:类诞生、成长甚至死亡的地方。包括伊甸园(Eden Space),幸存区0区以及幸存区1区。伊甸园区的对象是新产生的。如果在伊甸园区满后的垃圾回收 [轻GC] 后幸存(即仍然存在引用),就进入幸存区。幸存0区和1区相互之间会不断交换。
- 老年区: 若干次垃圾回收后对象仍然幸存,则进入老年区。
- 永久区(元空间 - jdk8之后改名):常驻内存的区域,可以被共享,不存在垃圾回收,只有关闭虚拟机才会释放内存。用来存放Java运行时的一些环境或类信息,包括JDK自身携带的Class对象,以及Interface元数据等。永久区处在堆外内存中。
在一些时候,永久区也会内存溢出。例如一个启动类,加载了大量的第三方jar包;Tomcat部署了太多的应用;大量动态生成的反射类。上述这些不断被加载,直到内存满,就会出现OOM。
拓展:经过研究,99%的对象都是临时对象。
GC垃圾回收,主要是在伊甸园区和老年区。垃圾回收的方式:
- 轻GC
- 重GC:Full GC
堆内存大小:默认最大为OS内存1/4,jvm初始化堆内存为OS内存1/64
1 | var maxMemory = Runtime.getRuntime().maxMemory(); |
堆内存也可以通过VM options参数来调整,例如:
1 | -Xms256m -Xmx1024m -XX:+PrintGCDetails |
若程序发生OOM,应该怎么排查问题呢?应该研究为什么出错~ 希望能够看到代码第几行出错
系统已经OOM挂了:
可提前设置VM选项,生成dump文件,然后使用内存快照分析工具,MAT,Jprofiler,VisualVM等
- 分析Dump内存文件,快速定位内存泄露(添加VM options:
-XX:+HeapDumpOnOutOfMemoryError可选指定路径-XX:HeapDumpPath=) - 获得堆中的数据、大的对象
- 分析Dump内存文件,快速定位内存泄露(添加VM options:
系统运行中还未OOM:
可在运行时导出dump文件(会导致一次Full GC,中断所有线程):
jmap -dump:format=b,file=xxx.hprof <pid>或者直接命令行显示:
jmap -histo:live <pid>或者使用Arthas工具来做分析和JVM调优
以Jprofiler工具为例,使用界面是这样的:
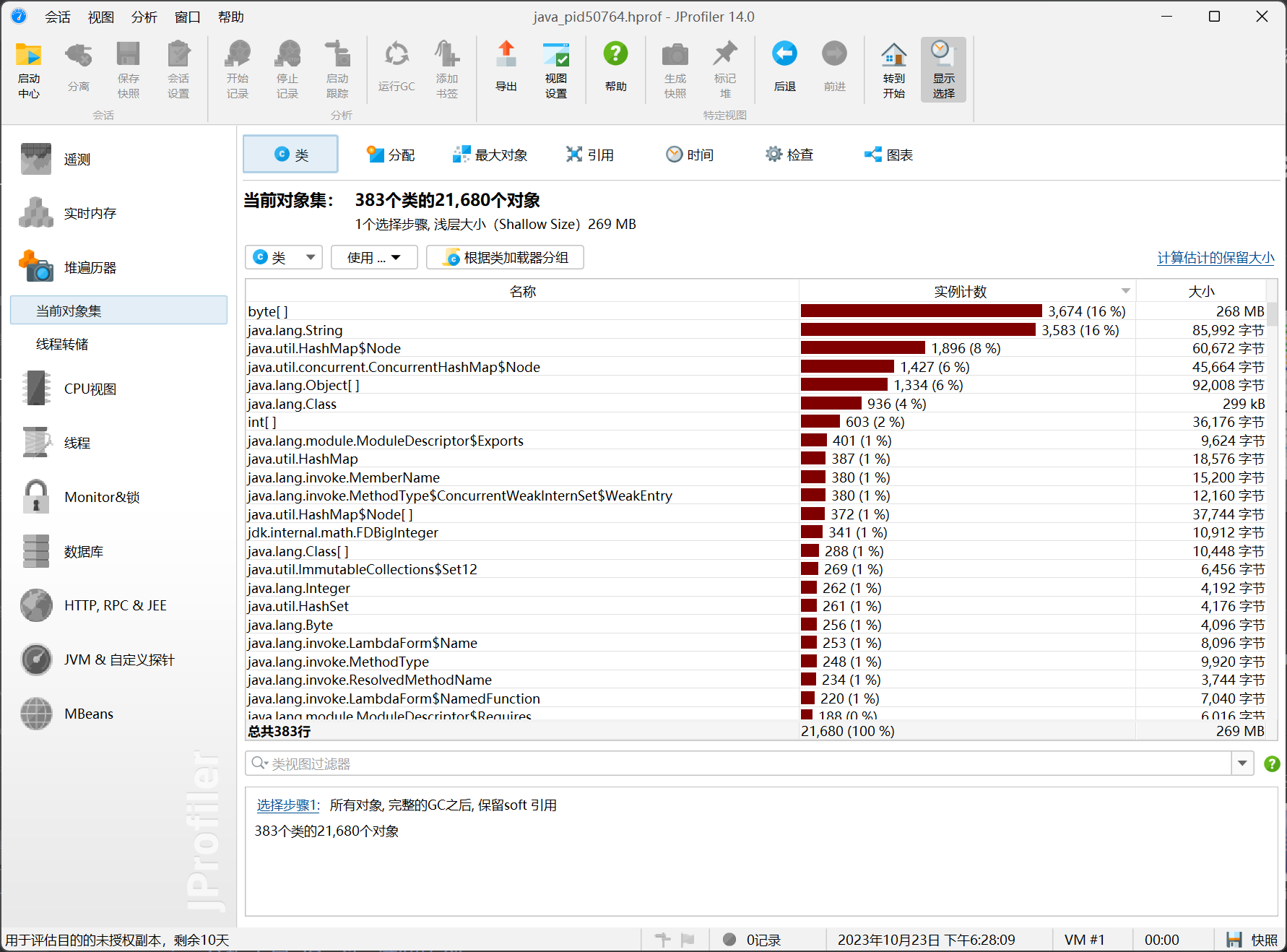
可以看到整个堆中的数据,并在“最大对象”中看占用内存最大的对象。同时,可以结合线程组分析问题代码的位置(例如下面就是在第13行出的问题):
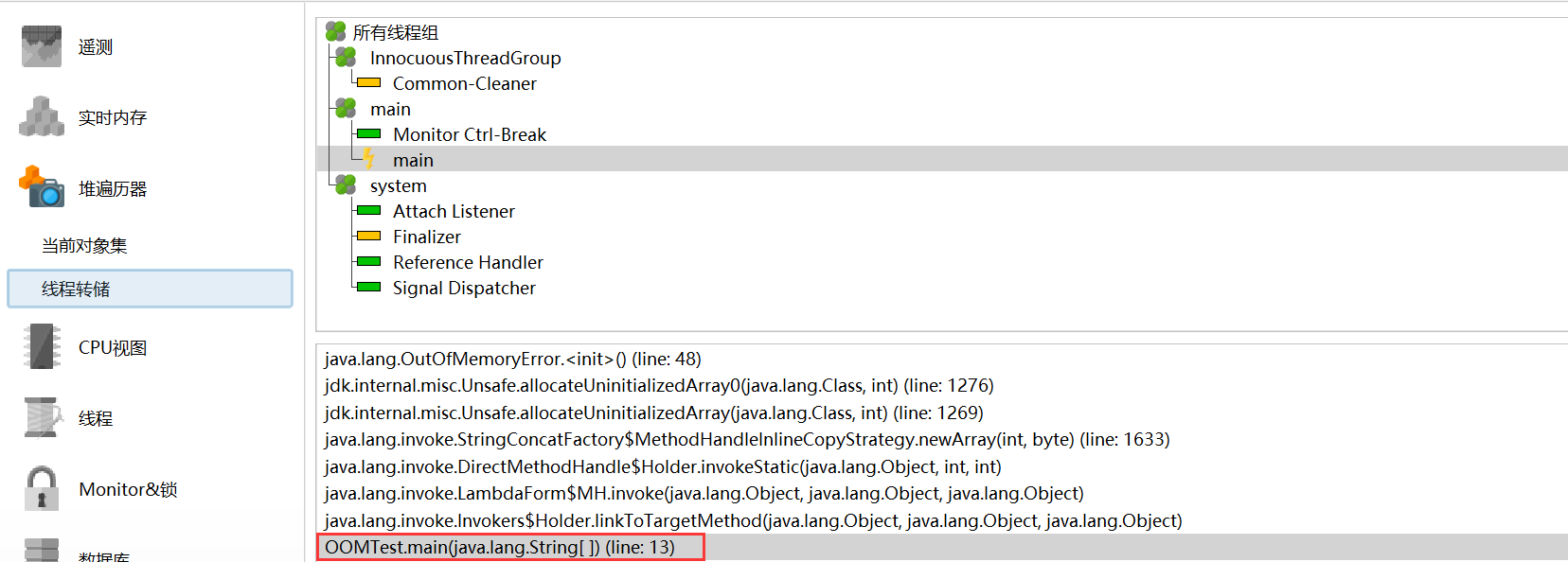
具体代码为:
1 | public class OOMTest { |
到这里,已经模拟了OOM,并有了真实的dump文件和问题分析的经验了!
JVM的种类
- SUN公司的Hotspot:聊到虚拟机时,若没做特殊说明,指的就是HotSpot。它是官方出品,纯正血统。它的特点/优势是:热点代码探测技术,通过计数器找到最具有编译价值的代码,触发即时编译器(JIT)或栈上替换
- BEA公司的JRockit:专注于服务器端应用,内部不包含解释器,全部代码都靠即时编译器编译执行,号称世界上最快的Java虚拟机
- IBM公司的J9:市场定位与Hotspot接近,服务端、桌面、嵌入式都有应用,若部署在IBM自己的产品上,号称是世界上最快的虚拟机。该虚拟机于2017年正式对外发布,名字为OpenJ9,并交给Eclipse基金会打理
曾经的三分天下,现在其二已被Oracle收购,不得不感叹,钞能力才是最终王者。
垃圾回收GC
引用计数法
最朴素简单的思想,给每个对象标记一个引用计数器。jvm一般不用这种方式的。

复制算法
之前介绍了新生区里面有幸存区0,1区,它们的角色是相互转换的。当某个为空的时候,它就是to区,另一个为from区。

复制算法主要用在新生代,具体过程:
- 每次GC都会将Eden区存活的对象移到幸存区中:一旦Eden区被GC后,它就会被清空;
- 幸存区两个区的角色(from/to)是互换的,每次GC将{from区中的对象} + {Eden区的对象} 全部转移到to区中,保证to区的干净;
- 当一个对象经过15次GC后,仍然存活,则进入老年区;(这个次数是可以调整的,
-XX:MaxTenuringThreshold=)
复制算法的优缺点:
- 好处:没有内存碎片
- 坏处:浪费内存空间(永远多一倍空间)
应用场景:对象存活度较低。因为存活度较高,那么复制拷贝成本高,存储开销也大。所以也是主要用在新生代。
标记清除算法
思路很简单,标记这次存活的对象,在GC的时候,清除没有标记的对象。
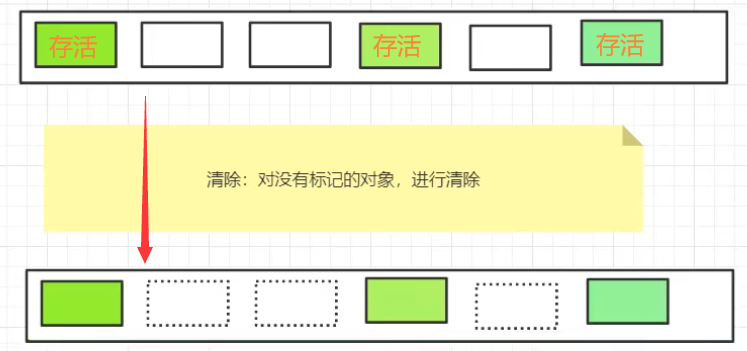
标记清除算法的优缺点:
- 优点:不需要额外的空间
- 缺点:两次扫描(标记-清除)会严重浪费时间,并且会产生内存碎片
标记压缩算法
其实就是优化了标记清除算法,再加一次扫描,向一端移动、整合存活的对象。

其压缩的过程,多了一次扫描和移动成本,但是消除了内存碎片。
其实 “标记清除” + “标记压缩” 一起并称为 标记清除压缩算法。
GC算法评价指标
GC算法中,结合实际使用场景,主要从下面三个指标来考虑:
- 内存效率:复制算法 > 标记清除算法 > 标记压缩算法 (时间复杂度)
- 内存整齐度:复制算法 = 标记压缩算法 > 标记清除算法
- 内存利用率:标记压缩算法 = 标记清除算法 > 复制算法
同时考虑以上三个指标,没有最好的算法,只有最合适的。—— 互联网没有银弹!
GC垃圾回收也被称为:分代收集算法
- 新生代:复制算法。[存活率低]
- 老年代:标记清除 + 标记压缩 混合实现。[区域大,存活率高]
所谓JVM在GC上的调优,其实就是调多少次进入老年代、标记清除多少次执行一次压缩等。
JMM
Java Memory Model,也即java内存模型。注意,JMM不是JVM的结构!
作用:JMM其实是个缓存一致性协议,用于定义数据读写的规则。
JMM定义了线程工作内存和主内存(Java进程只有一个主内存)之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory)。
可以解决共享对象可见性的问题:volatile关键字或者加锁
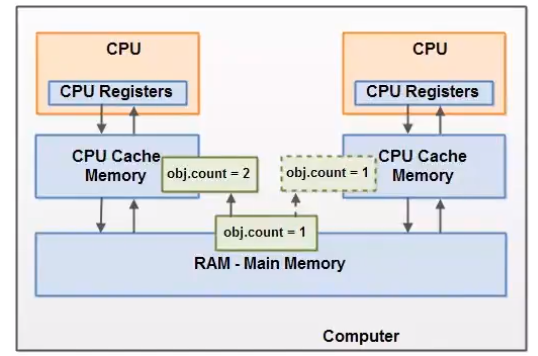
volatile关键字:如果线程中对共享对象做了改变,那么就会立即刷到主内存中,其他的线程就能够对最新共享对象可见。
更多内容参考:JMM(Java 内存模型)详解 | JavaGuide(Java面试 + 学习指南)
后续学习可以看书《深入理解JVM》、博客、视频教程(例如b站“遇见狂神说”相关JVM视频)等。

