一点背景
在当今数字化时代,互联网服务的普及使得大量的请求不断涌入系统,这使得有效的流量控制和资源管理成为至关重要的挑战。为了维护系统的可用性、稳定性以及提供更好的用户体验,限流算法应运而生。
在这个背景下,限流算法成为了互联网基础设施中的一项关键工具。这些算法的设计旨在:控制请求的访问速率,从而平衡系统的负载,防止过度请求引发的性能问题。限流不仅仅适用于服务器端,还在分布式系统、微服务架构等多个领域发挥着重要作用。例如Kafka作为一种消息中间件,在处理大量数据和消息时,通常需要实施限流策略以保护系统免受过载的影响。
本文就来挖掘一些常见的限流算法,了解这些算法的原理、如何实现、分析各自的优劣以及适应的场景。
常见限流算法
常见的限流算法有:计数器固定窗口、滑动窗口、漏斗以及令牌桶算法。下面对这几种算法进行分别介绍,并给出具体的实现。
计数器固定窗口算法
最基础、最简单的限流方式
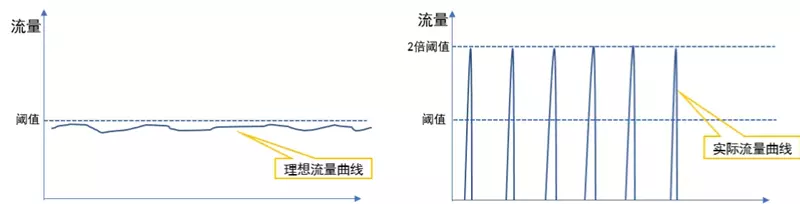
原理:对一段固定时间窗口内的请求进行计数,若请求数超过了阈值,则舍弃;否则接受并递增计数器。当时间窗口结束时,重置计数器。
示意图:

代码实现-Java:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| package com.zzmine.limiting;
import java.util.concurrent.atomic.AtomicInteger;
public class CounterLimiter {
private int windowSize;
private int threshold;
private AtomicInteger count;
public volatile boolean stopThread = false;
public CounterLimiter(int windowSize, int threshold){
this.windowSize = windowSize;
this.threshold = threshold;
count = new AtomicInteger(0);
new Thread(new Runnable() {
@Override
public void run() {
while(!stopThread){
try {
Thread.sleep(windowSize);
count.set(0);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
}
public boolean tryAccess(){
int newCurrCnt = count.addAndGet(1);
if(newCurrCnt > threshold){
return false;
}else{
return true;
}
}
public static void main(String[] args) throws InterruptedException {
CounterLimiter counterLimiter = new CounterLimiter(1000, 40);
int[] requestBatchs = {30, 50, 70, 90};
for(int k=0; k<requestBatchs.length; ++k){
int passCnt = 0;
for(int i=0; i<requestBatchs[k]; ++i){
if(counterLimiter.tryAccess()){
passCnt++;
}
}
System.out.printf("第%d波%d次请求中,通过:%d个.\n",k+1, requestBatchs[k], passCnt);
Thread.sleep(1000);
}
counterLimiter.stopThread = true;
}
}
|
优势:实现比较简单,而且也比较容易理解。
劣势:流量曲线不够平滑,可能有”流量突刺“的现象,并产生下面的两个问题。
无法应对短时间内的突发流量。例如一个时间窗口(1s)内有突发的高流量,限流为100,在窗口刚开始的1ms请求就达到了阈值,后面2ms-999ms内请求都将被拒绝,系统服务不可用。
窗口切换时可能会产生两倍于阈值的流量请求。例如在某窗口最后1ms达到了100个请求,然后下一个窗口的第1ms又到达了100个请求,这样会发现瞬时流量是阈值的两倍。
滑动窗口算法
是计数器固定窗口算法的改进,解决了固定窗口切换时可能会产生
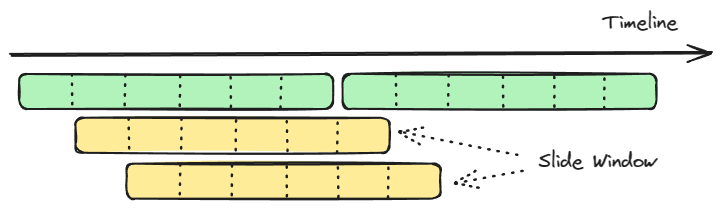
原理:1)滑动窗口算法在时间窗口的基础上引入了更灵活的机制,将整个窗口分割为多个小窗口,每个小窗口拥有独立的计数器。当请求的时间戳超出当前窗口的最大时间时,触发窗口的平移。2)这个平移过程包括丢弃第一个小窗口的数据,将第二个小窗口变为新的第一个,同时在末尾添加一个全新的小窗口来存储最新的请求。3)应该确保整个窗口中所有小窗口的请求总数不超过预设的阈值。In summary, 滑动窗口对请求数进行了更细粒度的限流,窗口划分的越多,则限流越精准。
示意图:
代码实现-Java:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
| package com.zzmine.limiting;
public class SlideWindowLimiter {
private int windowSize;
private int threshold;
private int windowNums;
private int[] counters;
private int currIdx;
private long startTime;
public SlideWindowLimiter(int windowSize, int threshold, int windowNums){
this.windowSize = windowSize;
this.threshold = threshold;
this.windowNums = windowNums;
counters = new int[windowNums];
currIdx = 0;
startTime = System.currentTimeMillis();
}
public synchronized boolean tryAccess(){
long currTime = System.currentTimeMillis();
int slideNums = (int) (Math.max(currTime - startTime - windowSize, 0)
/ (windowSize / windowNums));
slideWindow(slideNums);
int count = 0;
for(int i=0; i<windowNums; ++i){
count += counters[i];
}
if(count >= threshold){
return false;
}else{
counters[currIdx]++;
return true;
}
}
private synchronized void slideWindow(int slideNums){
if(windowNums == 0) {
return;
}
int realSlideNums = Math.min(slideNums, windowNums);
for(int i=0; i<realSlideNums; ++i){
currIdx = (currIdx + 1) % windowNums;
counters[currIdx] = 0;
}
startTime = startTime + slideNums * (windowSize / windowNums);
}
public static void main(String[] args) throws InterruptedException {
SlideWindowLimiter slideWindowLimiter =
new SlideWindowLimiter(1000, 40, 10);
int passCnt = 0, totalPass = 0;
int failCnt = 0, totalFail = 0;
System.out.println("滑动窗口限流算法:模拟100组间隔150ms的10次请求");
for(int i=0; i<50; ++i){
for(int j=0; j<10; ++j){
if(slideWindowLimiter.tryAccess()){
passCnt++;
}else{
failCnt++;
}
}
System.out.printf("第%d组请求中,通过:%d个,失败:%d个.\n",i+1, passCnt, failCnt);
totalPass += passCnt;
totalFail += failCnt;
passCnt = 0;
failCnt = 0;
Thread.sleep(150);
}
System.out.printf("一共请求了500次,通过了%d次,失败了%d次.", totalPass, totalFail);
}
}
|
优势:1)避免了计数器固定窗口算法在窗口切换时可能产生两倍于阈值流量的问题,使得流量更加稳定。2)与漏桶算法相比,新来的请求也能够被快速处理,避免饥饿问题。
劣势:算法实现略微复杂(但其实还好了
漏桶算法
比较形象的一个算法,类似漏斗。
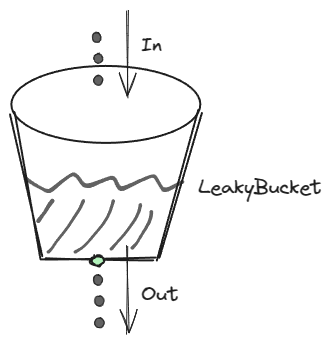
原理:请求到来后会进入到漏桶里,然后漏桶以恒定的速率将请求流出进行处理,从而起到平滑流量的作用。但是请求的流量过大时,漏桶达到最大容量并溢出,导致请求被丢弃。
示意图:
代码实现-Java:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
| package com.zzmine.limiting;
import java.util.Date;
import java.util.LinkedList;
public class LeakyBucketLimiter {
private int capacity;
private int rate;
private int left;
private LinkedList<Request> requests;
public LeakyBucketLimiter(int capacity, int rate){
this.capacity = capacity;
this.rate = rate;
left = capacity;
requests = new LinkedList<>();
new Thread(new Runnable(){
@Override
public void run(){
while(true){
if(!requests.isEmpty()){
Request request = requests.removeFirst();
handleRequest(request);
}
try {
Thread.sleep(1000 / rate);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
}
private void handleRequest(Request request) {
request.setHandleTime(new Date());
System.out.printf("%d号请求,发起时间:%s,处理时间:%s,处理耗时:%d ms\n",
request.getIndex(), request.getLaunchTime(), request.getHandleTime(),
request.getHandleTime().getTime() - request.getLaunchTime().getTime());
}
public synchronized boolean tryAccess(Request request){
if(left <= 0) {
return false;
}else{
left--;
requests.addLast(request);
return true;
}
}
static class Request{
private int index;
private Date launchTime;
private Date handleTime;
public Request(int index, Date launchTime){
this.index = index;
this.launchTime = launchTime;
}
public int getIndex() {
return index;
}
public void setIndex(int index) {
this.index = index;
}
public Date getLaunchTime() {
return launchTime;
}
public void setLaunchTime(Date launchTime) {
this.launchTime = launchTime;
}
public Date getHandleTime() {
return handleTime;
}
public void setHandleTime(Date handleTime) {
this.handleTime = handleTime;
}
}
public static void main(String[] args) {
LeakyBucketLimiter leakyBucketLimiter = new LeakyBucketLimiter(10, 2);
for(int i=0; i<20; ++i){
Request request = new Request(i, new Date());
if(leakyBucketLimiter.tryAccess(request)){
System.out.printf("%d号请求通过.\n", i);
}else{
System.out.printf("%d号请求被限流.\n", i);
}
}
}
}
|
优势:漏桶的漏出速率固定,可以平滑流量,对下游系统起到保护作用。
劣势:不能处理流量突发的问题,处理速度始终一致,流量突发时容易积水导致溢出。
Note: 漏斗算法不一定要按顺序处理请求,可根据不同实现安排优先级。
令牌桶算法
是对漏斗算法的一种改进,除了能够起到限流的作用外,还允许一定程度的流量突发。
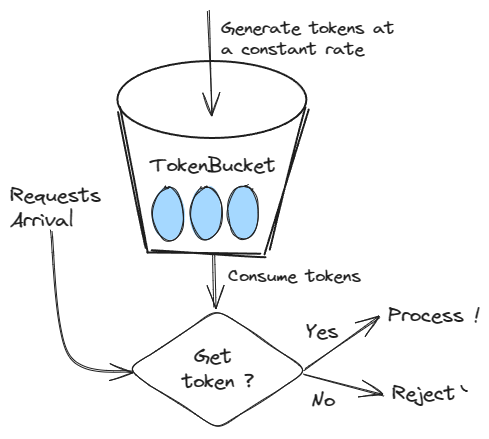
原理:假设有一个令牌桶,存在一种机制能以恒定的速率向令牌桶中放入令牌(但也存在最大容量)。当请求到来时,需要获得令牌才能被执行;若令牌桶为空,则请求被丢弃。
示意图:
代码实现-Java:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
| package com.zzmine.limiting;
import java.util.Date;
public class TokenBucketLimiter {
private int capacity;
private int rate;
private int tokenCnt;
public TokenBucketLimiter(int capacity, int rate){
this.capacity = capacity;
this.rate = rate;
tokenCnt = capacity;
new Thread(new Runnable() {
@Override
public void run() {
while(true){
synchronized (this){
tokenCnt++;
if(tokenCnt > capacity){
tokenCnt = capacity;
}
}
try {
Thread.sleep(1000/rate);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
}
public synchronized boolean tryAccess(Request request){
if(tokenCnt > 0){
tokenCnt--;
handleRequest(request);
return true;
}else{
return false;
}
}
private void handleRequest(Request request) {
request.setHandleTime(new Date());
System.out.printf("%d号请求,发起时间:%s,处理时间:%s,处理耗时:%d ms\n",
request.getIndex(), request.getLaunchTime(), request.getHandleTime(),
request.getHandleTime().getTime() - request.getLaunchTime().getTime());
}
static class Request {
private int index;
private Date launchTime;
private Date handleTime;
public Request(int index, Date launchTime) {
this.index = index;
this.launchTime = launchTime;
}
public int getIndex() {
return index;
}
public void setIndex(int index) {
this.index = index;
}
public Date getLaunchTime() {
return launchTime;
}
public void setLaunchTime(Date launchTime) {
this.launchTime = launchTime;
}
public Date getHandleTime() {
return handleTime;
}
public void setHandleTime(Date handleTime) {
this.handleTime = handleTime;
}
}
public static void main(String[] args) {
TokenBucketLimiter tokenBucketLimiter = new TokenBucketLimiter(10, 2);
for(int i=0; i<20; ++i){
Request request = new Request(i, new Date());
if(tokenBucketLimiter.tryAccess(request)){
System.out.printf("%d号请求通过.\n", i);
}else{
System.out.printf("%d号请求被限流.\n", i);
}
}
}
}
|
优势:能够平滑流量,同时还允许一定程度的突发流量
算法是死的,但是可以在实际场景中灵活运用。