致自己:朝着心中的目标努力奋斗!
Linux系统编程基础
Linux开发环境的配置
- Linux虚拟机
- XShell,Xftp连接软件
- VS Code远程代码连接
安装Ubuntu并安装openssh-server、net-tools:
1 | sudo apt install openssh-server |
VS Code安装插件C/C++、Remote Development,配置~/.ssh/config:
1 | Host Ubuntu18-webserver |
刷新一下,可以看到远程ssh连接了,在窗口中打开连接,选择Linux->continue然后输入密码就可以建立连接了。
GCC(GUN Compiler Collection)
GCC是由GNU开发的编程语言编译器,GNU编译器套件包括C、C++、Java、Go等。GCC支持C的许多“方言”,也可以区别不同的C语言标准。例如,使用命令行参数“-std=c99”启动GCC时,编译器支持C99标准。
安装GCC、G++:
1 | sudo apt install gcc g++ |
对C程序进行编译:
1 | gcc test.c -o app |
“-o”选项指定要生成的目标文件名称,成功生成后可以“./app”运行。
GCC的工作流程:预处理->编译->汇编->连接

相关编译命令:
| gcc编译选项 | 说明 |
|---|---|
| -E | 预处理指定的源文件,不进行编译 |
| -S | 编译指定的源文件,但不进行汇编 |
| -c | 编译、汇编指定的源文件,但不进行链接 |
| -o [file1] [file2] / [file2] -o [file1] |
将文件file2编译成可执行文件file1 |
| -I directory | 指定include包含文件的搜索目录 |
| -g | 在编译的时候,生成调试信息,该程序可以被调试器调试 |
| -D | 在程序编译的时候,指定一个宏 |
| -w | 不生成任何警告信息 |
| -Wall | 生成所有警告信息 |
| -On | n取值0~3. 编译器的优化等级,-O0表示不优化,-O1为缺省值 |
| -l | 在程序编译的时候,指定使用的库 |
| -L | 指定编译的时候,搜索的库的路径 |
| -fPIC / fpic | 生成与位置无关的代码 |
| -shared | 生成共享目标文件,通常用在建立共享库时 |
| -std | 指定c方言,如:-std=c99,gcc默认方言是GNU C |
gcc一般编译c文件,g++一般编译c++文件,但不是说绝对的。编译阶段,g++会调用gcc,两者是等价的,但是gcc不能自动和c++程序使用的库链接,所以通常使用g++来完成链接,且为了统一,干脆编译/链接全用g++了。
例如,编译时指定宏(能够方便程序的调试,调试时加debug编译发布的时候不加debug,这样就不用删去代码):
1 | // test.c |
那么如果编译时,不带“DEBUG”宏,就不会输出第一句话;如果这样编译,就会输出第一句话:
1 | gcc test.c -o test -D DEBUG |
静态库与动态库
库文件是一种代码仓库,它提供使用者一些可以直接拿来用的变量、函数或类。库是特殊的一种程序,不能单独运行。
库文件有两种,静态库和动态库(共享库),区别是:静态库在程序的链接阶段被复制到了程序中;动态库在链接阶段没有被复制到程序中,而是程序在运行时由系统动态加载到内存中供程序调用。
库的好处:1. 代码保密;2. 方便部署和分发。
静态库的制作与使用
命令规则:其中加粗部分是固定的
Linux: libxxx.a
Windows: libxxx.lib
其中的xxx就是库的名字,gcc -l(小L) 指定时只需要库的名字,不需要整个文件名
静态库制作方式:
gcc编译获得 .o 文件(仅 gcc -c)
将 .o 文件打包,使用 ar 工具(archive)
1
2
3
4
5ar rcs libxxx.a xxx.o xxx.o
-------------------
r: 将文件插入备存文件中
c: 建立备存文件
s: 索引
静态库的使用:
分级建立程序树状结构,生成静态库
1
2
3
4
5
6
7
8
9
10|- include
|--- head.h
|- lib
|--- libcalc.a
|- main.c
|- src
|--- add.c
|--- div.c
|--- mult.c
|--- sub.c1
ar rcs libcalc.a add.o div.o mult.o sub.o -I ../include/
利用 gcc “-I”(大i) 选项 指定自定义的头文件;“-L”(大L)选项指定库的搜索路径;“-l”(小L)选项指定所需的库:
1
gcc main.c -o app -I ./include/ -L ./lib -l calc
动态库的制作与使用
命名规则:其中加粗部分是固定的
Linux: libxxx.so 在Linux下是一个可执行文件
Windows: libxxx.dll
其中的xxx就是库的名字,使用时只需要库的名字,不需要整个文件名
动态库的制作方式:
gcc获得 .o 文件,得到和位置无关的代码
1
gcc -c -fpic a.c b.c [-I ../include/]
gcc 得到动态库
1
gcc -shared a.o b.o -o libcalc.so
动态库的使用:指定自定义头文件,“-L”(大L)选项指定库的搜索路径;“-l”(小L)选项指定所需的库:
1 | gcc main.c -o app -I ./include/ -L ./lib -l calc |
要解决动态库加载出现的问题,就需要先了解动态库的原理:
对于静态库,GCC进行链接时,会把静态库中代码打包到可执行程序中;
对于动态库,GCC进行链接时,只将动态库的信息放在程序中,动态库代码不会被打包到可执行程序中。程序启动之后,动态库会被动态加载到内存中,通过 ldd(list dynamic dependencies)命令检查动态库依赖关系。
1 | ldd main |
那么如何定位共享库文件呢?
当系统加载可执行代码时,能够知道其所依赖的库的名字,但还需要知道绝对路径。此时就需要系统的动态载入器(ld-linux.so)来获取该绝对路径。它会先后搜索可执行程序(基本都是elf格式,程序就是一个进程,OS会分配虚拟地址空间)的 DT_RPATH 段 —> 环境变量(PATH) —> LD_LIBRARY_PATH —> /etc/ld.so.cache 文件列表 —> /lib/ , /usr/lib 目录中,找到库文件后将其载入内存。
具体配置方式:
1,配置LD_LIBRARY_PATH
[临时的-终端中配置] 可以使用export命令,将动态库的绝对路径添加到 LD_LIBRARY_PATH中:(其中$表示取原来的值,“:”表示拼接,等号中间不要有空格)
1
2
3export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/zzmine/linux/lesson06/lib
env # 查看所有环境变量
echo $LD_LIBRARY_PATH # 查看 LD_LIBRARY_PATH 的值[永久的-用户级别配置] 到用户起始目录 /home/zzmine 中修改 .bashrc,添加上面的export语句:
1
2
3vim ~/.bashrc
... # 增加export LD_LIBRARY_PATH 语句
source ~/.bashrc[永久的-系统级别配置] 以管理者权限在 /etc/profile 中添加以上export语句:
1
2
3sudo vim /etc/profile
... # 增加export LD_LIBRARY_PATH 语句
source /etc/profile
2,配置 /etc/ld.so.cache
ld.so.cache 是二进制文件,不可以直接修改,但是可以间接修改 ld.so.conf
1 | sudo vim /etc/ld.so.conf |
不建议将自己的动态库文件放到 /lib/ 或者 /usr/lib/ 中,以防与系统自带的动态库发生冲突。
静态库与动态库的优缺点
| 优点 | 缺点 | 使用场景 | |
|---|---|---|---|
| 静态库 | 1,静态库打包到应用程序中加载速度快; 2,发布程序无需提供静态库,移植方便。 |
1,消耗系统资源,浪费内存(不同程序需要同一静态库,会占用多份内存空间); 2,更新、部署、发布麻烦。 |
库比较小 |
| 动态库 | 1,可以实现进程间资源共享; 2,更新、部署、发布简单; 3,可以控制何时加载动态库。 |
1,加载速度比静态库慢(但相差也不多); 2,发布程序时需要提供依赖的动态库。 |
库比较大 |
Makefile
一个工程中的源文件不计其数,其按类型、功能、模块分别放在若干个目录中,Makefile文件定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译。Makefile带来的好处就是“自动化编译”,一旦写好,只需要一个make命令,就可以自动编译整个工程。
Makefile文件命名和规则
文件命名:makefile 或者 Makefile
Makefile规则:
一个Makefile文件中可以有一个或多个规则。
1
2
3目标 ...: 依赖 ...
命令(Shell命令)
...目标:最终要生成的文件(伪目标除外)
依赖:生成目标所需要的文件或是目标
命令:通过执行命令对依赖操作生成目标(命令前必须Tab缩进)
Makefile中的其他规则一般都是为第一条规则服务的。如果下面的规则与第一条没有关系,就不会执行,除非手动指定目标。
Makefile工作原理
命令执行之前,需要检查规则中的依赖是否存在。
若存在,执行命令;
若不存在,向下检查其他规则,检查有没有一个规则是用来生成这个依赖的,如果找到了,则执行该规则中的命令。
检测更新,在执行规则中的命令时,会比较目标和依赖文件的时间。
如果依赖的时间比目标的时间晚,需要重新生成目标;
如果依赖的时间比目标的时间早,目标不需要更新,对应规则中的命令不需要被执行。
1 | app: sub.o add.o mult.o div.o main.o |
如果生成app之后,又修改了main.c,那么再次make仅会重新生成目标 main.o 和 app。
Makefile中的变量
上面的Makefile文件执行效率较高,但是写起来会很麻烦,有许多文件时需要写很多单独的语句。要进一步提高效率就需要了解Makefile中的变量。
自定义变量:没有数据类型,仅字符串
变量名=变量值
预定义变量:系统已经定义好
AR:归档维护程序的名称,默认值为ar
CC:C编译器的名称,默认值为cc
CXX:C++编译器的名称,默认值为g++
$@:目标的完整名称(包括后缀)
$<:第一个依赖文件的名称
$^:所有依赖文件
获取变量的值
$(变量名)
例如:
1 | # 自动变量只能在规则的命令中使用 |
模式匹配
%.o: %.c
%是通配符,匹配一个字符串,两个%匹配的是同一个字符串,例如:
1 | %.o:%.c |
函数
如果想自动获取src变量的值,就要使用到Makefile中函数的功能,例如:
1 | $(wildcard PATTERN...) |
1 | $(patsubst <pattern>,<replacement>,<text>) |
那么,上面例子的最终版Makefile将如下所示:
1 | src=$(wildcard ./*.c) |
GDB调试
GDB是由GNU软件系统社区提供的调试工具。
通常在为调试而编译时,会关闭编译器的优化选项(’-O’),并打开调试选项(’-g’)。另外,’-Wall’在尽量不影响程序行为的情况下打开所有warning,也可以发现许多问题,避免一些不必要的BUG。例如:
1 | gcc -g -Wall program.c -o program |
‘-g’选项的作用是在可执行文件中加入源代码的信息,例如可执行文件中第几条机器指令对应源代码的第几行,但并不是把整个源文件嵌入到可执行文件中,所以在调试时必须保证gdb能找到源文件。
GBD命令——启动、退出、查看代码
启动和退出:
1
2gdb 可执行程序
quit给程序设置参数:
1
2set args 10 20
show args使用帮助:help
查看当前文件代码
1
2
3list/l (从默认位置显示,10行)
list/l 行号 (从指定的行显示,指定行在中间)
list/l 函数名 (从指定函数显示)查看非当前文件代码
1
2list/l 文件名:行号
list/l 文件名:函数名设置显示的行数
1
2show list/listsize
set list/listsize 行数
GDB命令——断点
设置断点
1
2
3
4b/break 行号
b/break 函数名
b/break 文件名:行号
b/break 文件名:函数查看断点:i/info b/break
删除断点: d/del/delete 断点编号
设置断点无效:dis/disable 断点编号
设置断点生效:ena/enable 断点编号
设置条件断点(一般用在循环的位置):b/break 10 if i==5
GDB命令——调试
运行GDB程序
1
2start (程序停在第一行)
run (遇到断点才停)继续运行,到下一个断点停: c/continue
向下执行一行代码(不会进入函数体): n/next
变量操作
1
2p/print 变量名 (打印变量值)
ptype 变量名 (打印变量类型)向下单步调试(遇到函数进入函数体)
1
2s/step
finish(跳出函数体)自动变量操作
1
2
3display 变量名 (自动打印指定变量的值)
i/info display
undisplay 编号其他操作
1
2set var 变量名=变量值
until (跳出循环)
虚拟地址空间

内核空间中有进程控制块PCB,其中包含文件描述符表(默认大小1024),前3个文件描述符是默认的(标准输入,标准输出,标准错误)。后面每打开一个新文件,就占用一个文件描述符,且是空闲的最小的一个文件描述符。
TCP/IP协议
TCP/IP协议详解
TCP/IP协议族是一个四层协议系统,自底而上分别是数据链路层、网络层、传输层以及应用层。上层协议使用下层协议提供的服务。
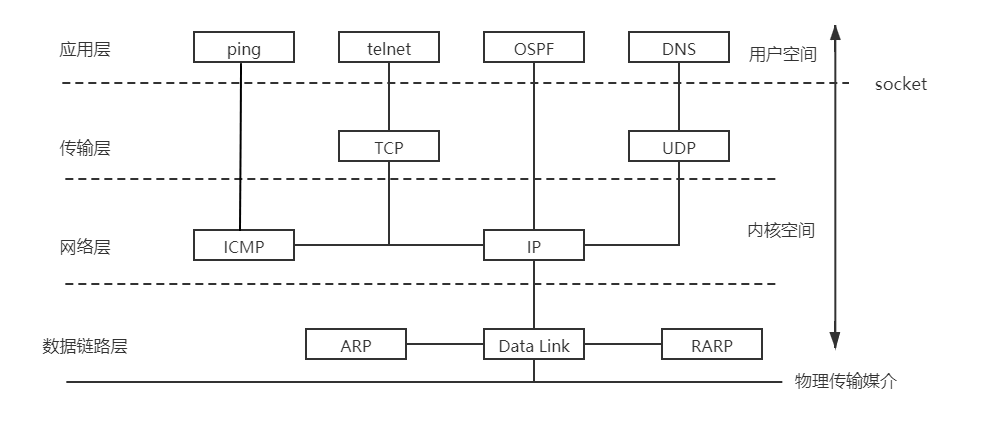
- 数据链路层【帧】:实现了网卡接口的网络驱动程序,以及处理数据在物理媒介(比如以太网、令牌环等)上的传输。常用协议有:ARP(Address Resolve Protocol, 地址解析协议)以及RARP(Reverse ARP, 逆地址解析协议)
- 网络层【数据报】:实现数据报的选路和转发。核心协议为IP协议(Internet Protocol, 因特网协议),IP协议使用逐跳(hop by hop)的方式确定通信路径。还有一个重要协议为ICMP协议(Internet Control Message Protocol, 因特网控制报文协议),用于检测网络连接。
- 传输层【报文段】:为两台主机上的应用程序提供端到端(end to end)的通信。主要有三个协议:TCP协议(Transmission Control Protocol, 传输控制协议),为应用层提供可靠的、面向连接的和基于流(steam)的服务;UDP协议(User Datagram Protocol, 用户数据报协议),为应用层提供不可靠、无连接和基于数据报的服务;以及SCTP协议(Stream Control Transmission Protocol, 流控制传输协议)。
- 应用层:处理应用程序的逻辑。数据链路层、网络层和传输层负责处理网络通信的细节,在内核空间中完成。而应用层负责处理众多逻辑,比如文件传输和网络管理等,在用户空间实现。应用层协议用很多,列举一些:ping,telnet,OSPF(Open Shortest Path First, 开放最短路径优先),DNS(Domain Name Service, 域名服务)
上层协议是如何使用下层协议提供的服务的呢?这是通过封装(encapsulation)实现的,封装指的是:
应用程序数据在发送到物理网络之前,将沿着协议栈从上往下依次传递。
每层协议都将在上层数据的基础上加上自己的头部信息(有时还包括尾部信息),以实现该层的功能。
帧是最终在物理网络上传输的字节序列,当帧到达目的主机时,将沿协议栈自底向上依次传递。各层协议栈处理帧中本层负责的头部数据,以获取所需信息,并最终将处理后的帧交给目标应用程序。这个过程成为分用(demultiplexing),即具体的使用下层服务的过程。
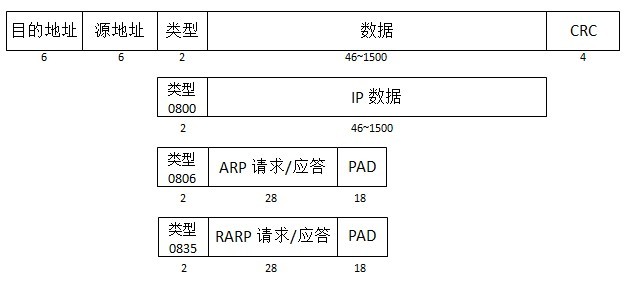
以太网帧(注意,物理网络上还有其他类型的帧)的MTU(Max Transmit Unit,最大传输单元)为1500. 其封装格式如下图:
由于数据链路层、网络层、传输层协议是在内核中实现的,因而操作系统需要一组系统调用,使应用程序能够访问这些协议提供的服务,这组系统调用就是socket。
socket是一套通用网络编程接口,不但可以访问内核中的TCP/IP协议栈,还可以访问其他网络协议栈(比如X.25协议栈,UNIX本地域协议栈等)。
ARP协议的工作原理
ARP协议能实现任意 网络层地址 到 物理地址 的转换。【本书只讨论从 IP地址 到 以太网MAC地址】
工作原理
主机向自己所在的网络 广播 一个ARP请求,该请求包含目标机器的网络地址。此网络上的其他机器都将收到这个请求,但只有被请求的目标机器会回应一个ARP应答,其中包含自己的物理地址。
ARP请求/响应报文格式
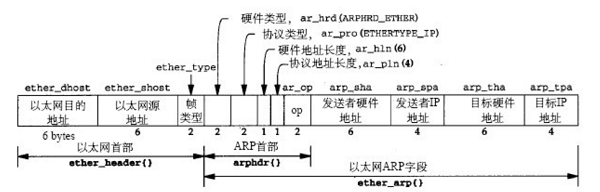
前面三个部分为以太网帧的首部,后面才是ARP报文。
ARP高速缓存
通常,ARP维护一个高速缓存,其中包含经常访问(比如网关地址)或最近访问的机器的IP地址到物理地址的映射。这样就避免了重复的ARP请求,提高了发送数据包的速度。
Linux中有如下相关命令:
1 | $ sudo arp -a # 显示arp缓存 |
还可以使用tcpdump命令来观察ARP通信的过程。
DNS工作原理
我们通常使用域名而不是IP地址来访问机器,那么如何将域名转化为IP地址呢?这就需要使用 域名查询服务。该服务有多种实现方式,比如NIS(Network Information Service, 网络信息服务),DNS和本地静态文件(hosts文件)。而这里主要讨论DNS。
DNS是一套分布式的域名服务系统,每个DNS服务器上都存放着大量的机器名称和IP地址的映射,并且是动态更新的。
DNS查询和应答报文
(略,见1.6.1)
Linux下访问DNS服务
Linux使用/etc/resolv.conf文件来存放DNS服务器的IP地址。
一个常用的访问DNS服务器的客户端程序是host,比如向DNS服务器查询www.baidu.com的IP地址:
1 | $ host -t A www.baidu.com |
使用tcpdump来抓包,观察DNS通信过程:
1 | $ tcpdump -i ens33 -nt -s 500 port domain |
IP协议详解
IP协议是TCP/IP协议族的核心协议,本章将从(1)IP头部信息以及(2)IP数据报的路由和转发,两个方面来深入探讨IP协议。在开始谈论前,先简单介绍一下IP服务。
IP服务的特点: 为上层协议提供无状态、无连接、不可靠的服务。
无状态:IP通信双方不同步传输数据的状态信息,因此所有IP数据报的发送、传输和接收都是相互独立的。
优点:简单,高效
缺点:无法处理乱序和重复的IP数据报
无连接:IP通信双方都不长久地维持对方的任何信息,因此上层协议每次发送数据报的时候,都必须指定对方的IP地址。
不可靠:不能保证IP数据报准确地到达接收端,可能因超时发送失败,也有可能校验发现数据不正确,因此使用IP服务的上层协议(如TCP)需要自己实现数据确认、超时重传等机制以达到可靠传输的目的。
弄清网络地址,主机地址以及子网掩码的区别
IP地址,是指互联网协议地址。IPv4地址是一个32位的二进制数,IPv6是一个128位的地址。IPv4通常用点分十进制的方式来表示,一个十进制数表示8个bit(如,192.168.1.1是二进制 11000000 10101000 00000001 00000001)。
IP地址的组成:网络号+主机号
而子网掩码,就是用来划分网络号和主机号。IP地址与子网掩码进行按位与操作,就能得到网络地址。通过该方式得到的网络地址相同,则说明两个IP地址处于同一个网络中,可以直接通信;否则,需要设置网关来进行通信。
举例:
| 名称 | 地址 | 二进制形式 |
|---|---|---|
| IP地址 | 192.168.1.108 | 11000000 10101000 00000001 01101100 |
| 子网掩码 | 255.255.255.0 | 11111111 11111111 11111111 00000000 |
| 网络地址 | 192.168.1.0 | 11000000 10101000 00000001 00000000 |
而IP地址通常可以分为五类:
| IP类别 | 网络标识 | 可支持的网络数目 | 主机标识 | 每个网络支持的主机数 |
|---|---|---|---|---|
| A类 | 前8位(左前1为0) | 2^7-1-1=126 | 后24位 | 2^24-2=16,777,214 |
| B类 | 前16位(左前2为10) | 2^14-1=16383 | 后16位 | 2^16-2=65,534 |
| C类 | 前24位(左前三为110) | 2^21-1=2097151 | 后8位 | 2^8-2=254 |
特殊类:
| IP类别 | 网络标识 | 可支持的网络范围 |
|---|---|---|
| D类 | 前4位为1110 | 224.0.0.0~239.255.255.255,D类地址用于组播(multicasting) |
| E类 | 前4位为1111 | 240.0.0.0~255.255.255.254,E类地址为保留地址 |
Tip:
关于可支持的网络数目:
每个类别的IP,网络号全0的地址不可分配,所以都需要减1
A类地址网络号全1时为127.x.x.x,但是该地址作为回环地址,不可使用,故还要减了1
关于每个网络支持的主机数:
主机号全0或全1的地址不可分配,所以都需要减2
其中A,B,C三类地址中各保留了一个区域作为私网地址,即供局域网使用。私网地址不能在公网上出现,只能用在内部网路中,所有路由器都不能发送目标地址为私网地址的数据报。
1 | A类私网地址:10.0.0.0 ~ 10.255.255.255 |
IPv4头部结构
IPv4头部结构如图所示,其长度通常为20字节,除非含有可变长的选项部分。
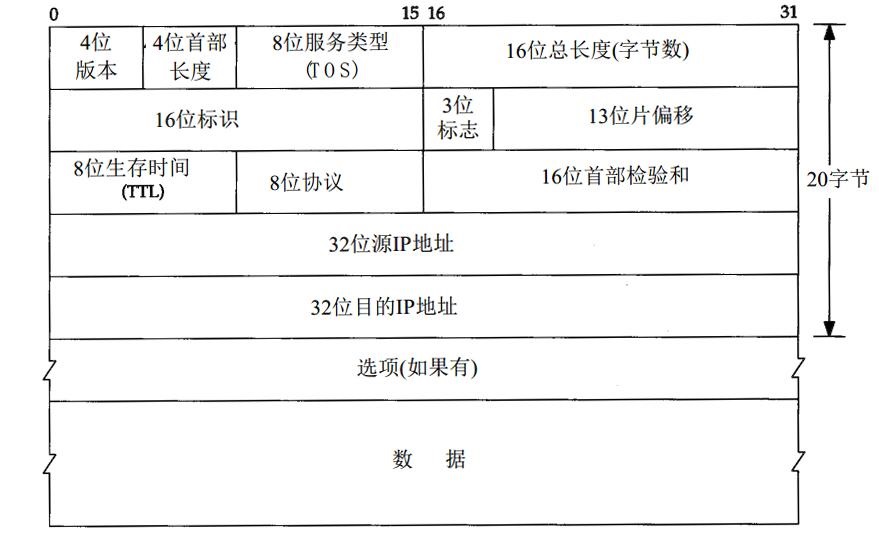
- 4位版本号:制定IP协议的版本,对IPv4来说,值是4。
- 4位头部长度:标识该IP头部有多少个32bit(4字节),最多有15个4字节,即最多60字节。
- 8位服务类型(TOS):包括一个3位的优先权字段(现已被忽略),4位TOS字段和一位保留字段(必须置0)。4位TOS分别表示:最小延迟,最大吞吐量,最高可靠性和最小费用。其中最多有一个能置为1。
- 16位总长度:指整个IP数据报的长度,以字节为单位,因此IP数据报的最大长度为65535(2^16-1)字节。但是由于帧的MTU限制,长度超过MTU的数据报都将被分片传输。
- 16位标识:唯一地标识主机发送的每一个数据报。其初始值由系统随机生成,每发送一个数据报,其值就加1.该值在数据报分片时被复制到每个分片中,因此同一个数据报的所有分片都具有相同的标识值。
- 3位标志:第一位保留;第二位(Don’t Fragment, DF)表示“禁止分片”,如果设置这个位,IP模块将不对数据报进行分片,长度超过MTU则丢弃并返回一个ICMP差错报文。第三位(More Fragment, MF)表示“分更多分片”,除了数据报的最后一个分片外,其他分片这一位都要置1.
- 13位分片偏移:分片相对于原始IP数据报开始处的偏移。实际的偏移值都是该值乘8得到的,所以除最后一个IP分片外,每个IP分片的数据部分长度必须是8的整数倍。
- 8位生存时间(Time To Live, TTL):是数据报到达目的地之前允许经过的路由器跳数。TTL值被发送端设置(通常是64)。数据报在转发过程中没经过一个路由,该值就被路由器减1. 当TTL值减为0时,路由器将丢弃数据报,并向源端发送一个ICMP差错报文。TTL值可以防止数据报陷入路由循环。
- 8位协议:用来区分上层协议。
/etc/protocols文件定义了所有上层协议对应的protocol字段的数值。其中ICMP是1,TCP是6,UDP是17. 【/etc/services文件定义了应用程序的端口号】 - 16位头部校验和:由发送端填充,接收端使用CRC算法以检验IP数据报头部在传输过程中是否损坏。
- 32位源端和目的端IP地址:标识数据报的发送端和接收端。一般情况下,这两个地址在整个数据报的传递过程中保持不变。
- 可用的IP选项包括:记录路由(记录经过的路由器);时间戳(记录被转发的时间);松散源路由选择(指定一个路由器IP地址列表,数据报发送过程中必须经过其中所有的路由器);严格源路由选择(指定路由IP地址列表,数据报只能经过被指定的路由器)
使用tcpdump观察IPv4头部结构
为了深入理解IPv4头部中每个字段的含义,我们利用tcpdump抓取telnet服务的数据报:
1 | $ sudo tcpdump -ntx -i lo |
【提示】如果telnet 127.0.0.1 出现 telnet: Unable to connect to remote host: Connection refused,那么可以检查一下telnet是否启动。见:解决Ubuntu中telnet 127.0.0.1时Unable to connect to remote host: Connection refused的问题 - 简书 (jianshu.com)
开启了抓包的 -x 选项,将数据数据包的二进制内容。此数据包共60字节,前20为IP头部,后40为TCP头部,不含应用程序数据(length为0)。
| 十六进制数 | 二进制数/十进制数 | IP头部信息说明 |
|---|---|---|
| 0x4 | 4 | IP版本号(IPv4为4) |
| 0x5 | 5 | 头部长度5个32位,即20字节 |
| 0x10 | ‘0001 0000 | TOS选项中最小延时被开启 |
| 0x003c | 60 | 数据报总长度60字节 |
| 0x0995 | 数据报标识 | |
| 0x4 | ‘0100 | 设置了禁止分片 |
| 0x000 | 0 | 分片偏移为0 |
| 0x40 | 64 | TTL为64 |
| 0x06 | 6 | 协议字段为6,对应上层协议为TCP |
| 0x3315 | IP头部校验和 | |
| 0x7f00 0001 | 32位源端IP:127.0.0.1 | |
| 0x7f00 0001 | 32位目的端IP:127.0.0.1 |
由此可见,telnet选择使用具有最小延时的服务。
IP分片
当IP数据报的长度超过帧的MTU时,它将被分片传输。而分片可能发生在发送端,也可能发生在中转路由器上,而且可能在传输过程中被多次分片,但只有在最终的目标机器上,这些分片才会被内核中的IP模块重新组装。
通过数据报标识、标志和分片偏移这三个字段的信息,可以完成IP的分片和重组。
一个IP数据包的每个分片都具有自己的IP头部,它们具有先相同的标识值,但片偏移不同。并且除了最后一个分片外,其他分片都将设置MF标志。此外,每个分片的IP头部总长度字段将被设置为该分片的长度。
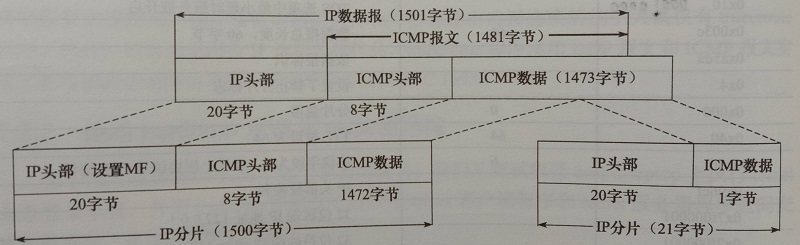
以太网帧的MTU为1500字节,因此它携带的IP数据报的数据部分最多是1480字节(头部占20字节时)。假设一个长度为1481字节的ICMP报文(包含8字节的ICMP头部,以及数据部分1473字节),则该数据报在使用以太网帧传输时必须要被分片,如下图所示。
使用tcpdump来验证这一分片的情况:
1 | $ sudo tcpdump -ntv -i eth0 icmp |
可以看到,两个分片标识都是一样的,为61197,说明是同一个数据报的分片;第一个分片的偏移(offset)为0,而第二个为1480;第一个分片的flags [+]表示MF标志,即更多分片,而第二个分片则没有设置标志;两个分片的长度分别为1500和21字节。
IP路由
IP协议的一个核心任务是数据报的路由,即决定发送数据报到目标机器的路径。
先简要分析IP模块的基本工作流程。
IP模块工作流程
IP模块基本工作流程如下图:
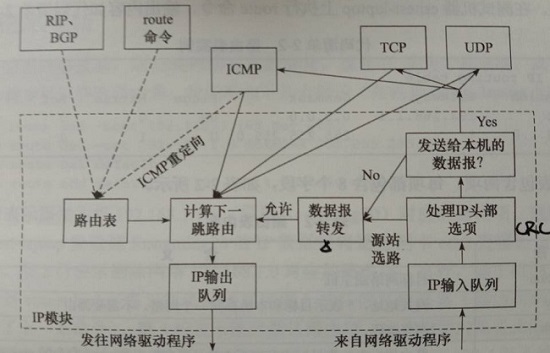
从右往左看,IP模块接到来自数据链路层的IP数据报时,首先对头部进行CRC校验,确认无误后分析头部信息。
如果数据报设置了源站选路选项(松散源路由选择或严格源路由选择),则IP模块调用数据报转发子模块来处理该数据报。如果数据报目标IP地址是本机的某个IP或者广播地址,就根据头部中的协议字段将它派分到对应的上层应用(分用)。如果数据报不是发到本机的,就调用数据报转发子模块来处理。
数据报转发子模块首先检测系统是否允许转发,如果不允许就将数据报丢弃,否则经过一些操作后交给数据报输出子模块。
IP模块实现数据报路由的核心数据结构是路由表。这个表按照数据报的目标IP地址分类,同一类型的IP数据报将被发往相同的下一跳路由器(或者目标机器)。
IP输出队列存放的是所有等待发送的IP数据报,其中除了需要转发的IP数据报外,还包括封装了本机上层数据(ICMP报文、TCP报文段和UDP数据报)的IP数据报。
路由机制
可以使用route命令或者netstat命令来查看路由表,以下是route命令的输出内容:
1 | $ sudo route |
该路由表包括两项,每项都有8个字段。
| 字段 | 含义 |
|---|---|
| Destination | 目标网络或主机 |
| Gateway | 网关地址,*表示目标和本机在同一网络,不需要路由 |
| Genmask | 网络掩码 |
| Flags | 路由项标志,常见的标志有如下5种: 1,U:该路由项是活动的; 2,H:该路由项的目标是一台主机; 3,G:该路由项的目标是网关; 4,D:该路由项是由重定向生成的; 5,M:该路由项被重定向修改过 |
| Metric | 路由距离,即到达指定网络所需的中转数 |
| Ref | 路由项被引用的次数(Linux未使用) |
| Use | 该路由项被使用的次数 |
| Iface | 该路由项对应的输出网卡接口 |
以上路由表中的第一条记录,目标地址为default,即所谓的默认路由项。第二条路由项的目标地址为192.168.1.0,指的是本地局域网,网关地址为*,说明数据报不需要路由中转,是直达的。
IP路由的匹配机制:
- 查找路由表中和数据报的目标IP地址完全匹配的项
- 查找与数据报的目标IP地址具有相同网络号的网络IP地址(如第二项)
- 选择默认路由项
路由表更新
路由表必须能够更新,以反映网络连接的变化。使用route命令可以修改路由表:
1 | $ sudo route add -host 192.168.1.109 dev eth0 |
其中,第一行表示添加主机192.168.1.109对应的路由项,所有到该主机的IP数据报将通过网卡eth0传输。第二行表示删除网络192.168.1.0对应的路由项,结果是无法访问局域网上的任何机器(除刚刚添加192.168.1.109)。第三行表示删除默认路由项。第四行表示添加默认路由项,不过网关为192.168.1.109,而不是可以直接访问因特网的路由器。
修改后的路由表如下:
1 | Destination Gateway Genmask Flags Metric Ref Use Iface |
注意,新的路由项Flags也不同,其中第一条中的Flags为UH,表示主机路由项。
通过route命令或其他工具手工修改路由表,是静态的路由更新方式。对于大型路由器,他们通常通过BGP(Border Gateway Protocol, 边际网关协议)、RIP(Routing Information Protocol, 路由信息协议)、OSPF等协议来发现路径,并更新自己的路由表。
IP转发
之前提到,不发送给本机的IP数据报将由数据报转发子模块来处理。路由器可以转发数据报,但主机一般只发送和接收数据报,这是因为主机上/proc/sys/net/ipv4/ip_forward内核参数默认被设置为0。我们可以通过修改该参数来启用主机数据报转发(root身份执行):
1 | $ echo > 1 /proc/sys/net/ipv4/ip_forward |
对于允许IP数据报转发的系统(路由器或主机),数据报转发子模块将对期望转发的数据报执行以下操作:
- 检查数据报头部TTL值。0则丢弃。
- 查看数据报头部的严格源路由选项。如果被设置,则检测数据报的目标IP地址是否为本机的某个IP地址。如果不是,则发送一个ICMP源站选路失败报文给发送端。
- 如果有必要,给源端发送一个ICMP重定向报文,告诉它一个更合理的下一跳路由器。
- 将TTL值减1。
- 处理IP头部选项。
- 如果有必要,执行IP分片操作。
重定向
IP模块基本流程图中显示,ICMP重定向报文也能更新路由表,这里就简要讨论一下。
ICMP重定向报文

ICMP重定向报文的类型值是5,代码字段有4个可选值(0-3),用来区分不同的重定向类型,本文讨论主机重定向,其代码值为1。
该报文给接收方提供了如下两个信息:
- 引起重定向的IP数据报的源端IP地址(IP数据报头部信息中)
- 应该使用的路由器的IP地址
接收主机根据这两个信息就可以断定引起重定向的IP数据报应该使用那个路由器来转发,并且以此来更新路由表(通常是更新路由表缓冲,而不是直接更改路由表)。
/proc/sys/net/ipv4/conf/all/send_redirects内核参数指定是否允许发送ICMP重定向报文,而/proc/sys/net/ipv4/conf/all/accept_redirects内核参数则指定是否允许接收ICMP重定向报文。一般来说,主机只能接收ICMP重定向报文,而路由器只能发送ICMP重定向报文。
TCP协议详解
传输层协议主要有两个:TCP协议和UDP协议。TCP相对于UDP的特点是:面向连接、字节流和可靠传输。
面向连接。
使用TCP通信的双方必须先建立连接,然后才能开始数据的读写。
TCP连接是全双工的,即双方的数据读写可以通过一个连接进行。
TCP连接是一对一的,所以基于广播或多播(目标是多个主机地址)的应用程序不能使用TCP服务。
字节流。
TCP发送端执行的写操作次数和接收端执行的读操作次数之间没有任何数量关系。
而UDP发送端应用程序每执行一次写操作,UDP模块就将其封装成一个UDP数据报并发送,接收端必须及时针对每一个UDP数据报执行读操作。
可靠传输。
TCP协议采用发送应答机制,即发送端发送的每个TCP报文段都必须得到接收方的应答,才认为这个TCP报文段传输成功。
TCP协议采用超时重传机制,发送端在发送出一个报文段之后会启动定时器,如果在定时时间内未收到应答,它将重发该报文段。
会对接到的TCP报文段重排、整理(因为TCP报文段最终是以IP数据报发送的),再交给应用层。
这一章从以下四个方面来讨论TCP协议:
TCP头部信息。
用l于指定通信的源端端口号、目的端端口号,管理TCP连接,控制两个方向的数据流。
TCP状态转移过程。
TCP连接的任意一端都是一个状态机。在TCP连接从建立到断开的整个过程中,连接两端的状态机将经历不同的状态变迁。
TCP数据流。
讨论两种类型的TCP数据流:交互数据流和成块数据流。
TCP数据流的控制。
为了保证可靠传输和提高网络通信质量,内核需要对TCP数据流进行控制。主要讨论超时重传和拥塞控制。
TCP头部结构
固定头部结构
TCP头部结构如下,其中诸多字段为管理TCP连接和控制数据流提供了足够的信息。
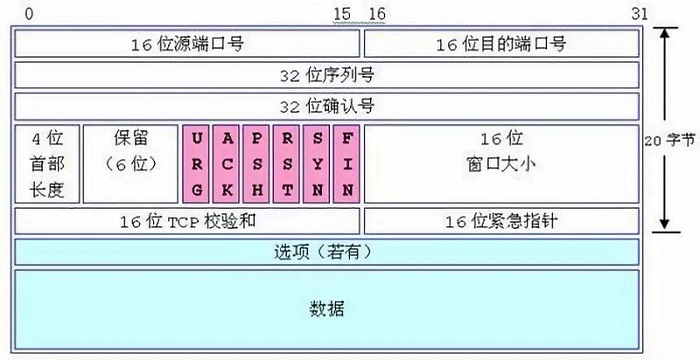
- 16位端口号:表示该报文段的源端和目的端端口号。TCP通信时,客户端通常使用系统自动选择的临时端口号,而服务器则使用知名服务端口号(见
/etc/services文件)。 - 32位序号:一次TCP通信过程中某个传输方向上的字节流的每个字节的编号。序号值被系统初始化为某个随机值ISN(Initial Sequence Number),后续TCP报文段的序号值为ISN加上该报文段所携带数据的第一个字节在整个字节流中的偏移。
- 32位确认号:用作对源端发送来的TCP报文段的响应。其值为收到的TCP报文段序号值加 1。
- 4位头部长度:表示该TCP头部有多少个32bit(4字节)。TCP头部最长为60字节。
- 6位标志分别是:
- URG标志:表示紧急指针是否有效。
- ACK标志:表示确认号是否有效。携带ACK标志的TCP报文段为
确认报文段。 - PSH标志:提示接收端应用程序应该立即从TCP接收缓冲区中读走数据,为接收后续数据腾出空间。
- RST标志:表示要求对方重新建立连接。携带RST标志的TCP报文段为
复位报文段。 - SYN标志:表示请求建立一个连接。携带SYN标志的TCP报文段为
同步报文段。 - FIN标志:表示通知对方本端要关闭连接了。携带FIN标志的TCP报文段为
结束报文段。
- 16位窗口大小:是TCP流量控制的一个手段。接收通告窗口(Receiver Window, RWND)告诉对方本端的TCP接收缓冲区还能容纳多少字节的数据,这样对方就可以控制发送数据的速度。
- 16位校验和:由发送端填充,接收端对TCP报文段执行CRC算法校验TCP报文段在传输过程中是否损坏。注意,这个校验不仅包括TCP头部,也包括数据部分。这是TCP可靠传输的一个重要保障。
- 16位紧急指针:一个正的偏移量。它和序号相加表示最后一个紧急数据的下一字节的序号。
TCP头部选项
TCP头部最后一个选项字段是可变长的可选信息。这部分最多包含40字节。TCP头部选项的一般结构如下:

第一个kind字段说明选项的类型。有的TCP选项没有后面两个字段。第二个length字段指定该选项的总长度,该长度包括kind和length占据的2字节。第三个info是选项的具体信息。
常见的TCP选项有7种:
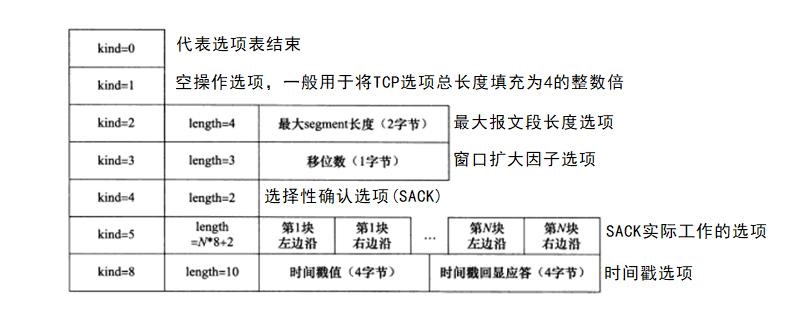
kind=0是选项表结束选项。
kind=1是空操作(nop)选项。一般用于将TCP选项的总长度填充为4字节的整数倍。
kind=2是最大报文段长度选项。TCP连接初始化时(同步报文段),通信双方用该选项协商最大报文段长度(Max Segment Size, MSS)。TCP模块通常将MSS设置为(MTU-40)字节,减去的为TCP和IP的头部各20字节。
kind=3是窗口扩大因子选项。也是在同步报文段中出现,接收通告窗口大小用16位表示,即最大65535字节,但实际上TCP模块允许的窗口大小远不止这个数(为了提高TCP通信的吞吐量)。窗口扩大因子解决了这个问题,若TCP头部的接收通告窗口大小为N,窗口扩大因子为M,则TCP报文段的实际接收通告窗口大小为(N<<M),M取值范围为0~14。{可以通过修改/proc/sys/net/ipv4/tcp_window_scaling内核变量来启用或者关闭窗口扩大因子选项}
注意,同步报文段本身不执行窗口扩大操作,即同步报文段头部的接收通告窗口大小就是该TCP报文段的实际接收通告窗口大小。
kind=4是选择性确认(Selective Acknowledgment, SACK)选项。TCP通信时,如果某个TCP报文段丢失,则TCP模块会重传最后被确认的TCP报文段后续的所有报文段,不过这样原来已经正确传输的TCP报文段也可能重复发送,从而降低了TCP的性能。SACK技术解决了这个问题,它使TCP模块只重新发送丢失的TCP报文段。{可以通过修改/proc/sys/net/ipv4/tcp_sack内核变量来启用或者关闭选择性确认选项}
kind=5是SACK实际工作的选项。该选项的参数告诉发送方本端已经收到并缓存的不连续的数据块,从而让发送端可以据此检查并重发丢失的数据块。
kind=8是时间戳选项。该选项提供了较为精准的计算通信双方之间的回路时间(Round Trip Time, RTT)的方法,从而为TCP流量控制提供重要信息。{可以通过修改/proc/sys/net/ipv4/tcp_timestamps内核变量来启用或者关闭时间戳选项}
使用tcpdump观察TCP头部信息
在上一章使用tcpdump进行抓包,分析了IPv4的头部,这里继续看这个数据包中的TCP头部信息。
1 | IP 127.0.0.1.46024 > 127.0.0.1.23: Flags [S], seq 2327807816, win 32792, options [mss 16396,sackOK,TS val 40781017 ecr 0,nop,wscale 6], length 0 |
Flags [S],表示该TCP报文段包含SYN标志,因此是一个同步报文段。
seq是序号值,因为是从127.0.0.1.46024到127.0.0.1.23的第一个报文段,该序号值就是此次通信过程中该传输方向的ISN值。并且,因为是整个传输过程中的第一个报文段,它并没有针对对方报文段的确认值。
win是接收通告窗口的大小。因为是同步报文段,所以win值反映的是该报文段的实际接收通告窗口大小。
options是TCP选项,具体内容在方括号中。mss是发送端通告的最大报文段长度,通过ifconfig命令查看回路接口的MTU为16436字节,因此可以预想MSS为(16436-40,即16396字节);sackOK表示发送端支持并同意使用SACK选项;TS val是发送端的时间戳;ecr是时间戳的回显应答。因为是第一个报文段,所以它针对对方的时间戳的应答为0(表示未收到对方的时间戳);nop是一个空操作选项;wscale指出发送端使用的窗口扩大因子为6。
接下来分析tcpdump输出的字节码中TCP头部对应的信息,它从第21字节开始。
| 十六进制数 | 十进制/二进制表示 | TCP头部信息 |
|---|---|---|
| 0xb3c8 | 46024 | 源端口号 |
| 0x0017 | 23 | 目的端口号 |
| 0x8abf 8748 | 2327807816 | 序列号 |
| 0x0000 0000 | 0 | 确认号 |
| 0xa | 10 | TCP头部长度为10个32bit(40字节) |
| 0x002 | ‘0000 0000 0010 | 前六位保留,标志位设置了SYN |
| 0x8018 | 32792 | 接受通告窗口大小 |
| 0xfe30 | 校验和(此时没有数据,就只有头部) | |
| 0x0000 | 没有设置紧急指针 | |
| 0x0204 | 最大报文段长度选项的kind和length值 | |
| 0x400c | 16396 | 最大报文段长度【4-2得到2字节表示该值】 |
| 0x0402 | 允许SACK选项 | |
| 0x080a | 时间戳选项的kind和length值 | |
| 0x026e 44d9 | 40781017 | 时间戳 |
| 0x0000 0000 | 0 | 回显应答时间戳 |
| 0x01 | 空操作 | |
| 0x0303 | 窗口扩大因子选项的kind和length值 | |
| 0x06 | 6 | 窗口扩大因子为6 |
TCP连接的建立和关闭
三次握手,四次挥手的过程:
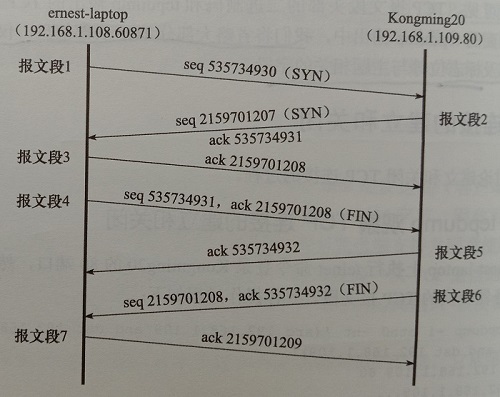
连接建立(三次握手):
第一个报文段包含SYN标志,是一个同步报文段,即ernest-laptop向Kongming20发起连接请求。该报文段中包含一个ISN值为535734930的序号。
第二个报文段也是一个同步报文段,表示Kongming20同意与ernest-laptop建立连接。同时发送自己ISN值为2159701207的序号,并对第一个报文段进行确认。
第三个报文段对第二个报文段进行确认。至此,TCP连接建立。
注意,从第三个报文段之后,tcpdump输出的序号值和确认值都是相对于初始ISN值的偏移(图中不是偏移),也可以用tcpdump的-S选项来打印序号的绝对值。
连接关闭(四次挥手):
第四个报文段包含FIN标志,因此它是一个结束报文段,即ernest-laptop要求关闭连接。
Kongming20用TCP报文段5来确认对方的结束报文段。(可省略,因为6也包含了确认信息)
Kongming20发送自己的结束报文段6。
ernest-laptop用TCP报文段7来予以确认。
在这里,是ernest-laptop先发送结束报文段,故称ernets-laptop执行主动关闭,而Kongming20执行被动关闭。
半关闭状态
TCP连接是全双工的,所以它允许两个方向的数据传输被独立关闭。
也就是说,通信的一方可以发送结束报文段给对方,表明自己本端已经完成了数据的发送,但是却允许继续接收来自对方的数据,直到对方也发送结束报文段以关闭连接。这种状态称为半关闭状态,如下图所示。
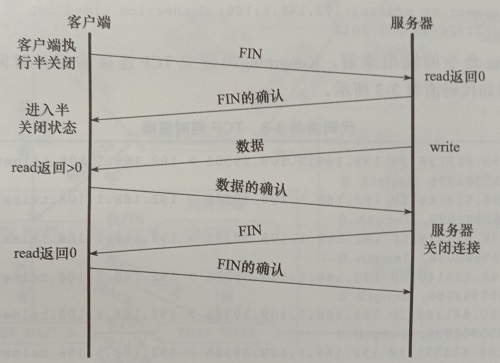
注意,图中服务器和客户端应用程序判断对方是否已经关闭连接的方法是:read系统调用返回0(即收到结束报文段)。
socket网络编程接口通过shutdown函数提供了对半关闭的支持。
虽然介绍了半关闭状态,但是使用半关闭的应用程序很少见。
连接超时
如果客户端访问一个距离它很远的服务器,或者由于网络繁忙,导致服务器对于客户端发送出的同步报文段没有应答,此时客户端程序将产生什么样的行为呢?
对于提供可靠服务的TCP来说,必然是先进行重连(可能执行多次),如果重连仍无效,则通知应用程序连接超时。可以使用iptable来过滤数据报,丢弃同步报文段来模拟实验。
实验过程略(见书P40)。
TCP状态转移
TCP链接的任意一端在任一时刻都处于某种状态,当前状态可以通过netstat命令查看。
下面是完整的状态转移图:

粗虚线表示服务器端的状态连接;粗实线表示客户端的状态连接。CLOSED是一个假想的起始点,并不是一个实际的状态。
TCP状态转移总图
先来看服务器的典型状态转移过程。
服务器通过listen系统调用进入LISTEN状态,被动等待客户端连接(即,被动打开)。服务器一旦监听到某个连接请求(收到同步报文段),就将该连接放入内核等待队列中,并向客户端发送带SYN标志的确认报文段。此时该连接处于SYN_RCVD状态。如果服务器成功地接收到客户端发送回的确认报文段,则该连接转移到ESTABLISHED状态。
当客户端主动关闭连接时(通过close或shutdown系统调用,向服务器发送结束报文段),服务器通过返回确认报文段使连接进入CLOSE_WAIT状态。等待服务器应用程序关闭连接。待服务器向客户端发送结束报文段,就使得连接进入LAST_ACK状态,以等待客户端对结束报文段的最后一次确认。一旦确认完成,连接就彻底关闭了。
下面讨论客户端的典型状态转移过程。
客户端通过connect系统调用(向服务器发送一个同步报文段)主动与服务器建立连接,使连接转移到SYN_SENT状态。不过,connect系统调用可能因为如下两个原因而失败:
- connect连接的目标端口不存在(未被服务器任何进程监听),或者该端口仍被处于TIME_WAIT状态的连接所占用(见后文),则服务器将给客户端发送一个复位报文段,connect调用失败;
- 若端口存在,但connect在超时时间内未收到服务器的确认报文段,则connect调用失败。
connect调用失败将使连接立即返回设想的CLOSED状态。若客户端成功收到服务器的同步报文段和确认,则connect调用成功返回,连接转移至ESTABLISHED状态。
客户端执行主动关闭时,将向服务器发送一个结束报文段,同时进入FIN_WAIT_1状态。若收到服务器的确认报文段,连接就能转移到FIN_WAIT_2状态。当客户端处于FIN_WAIT_2状态时,服务器处于CLOSE_WAIT状态,这一对状态是可能发生半关闭的状态。此时如果服务器也关闭连接,则客户端将给予确认并进入TIME_WAIT状态。
图中还描绘了其他非典型的TCP状态转移路线,比如同时关闭与同时打开,不作讨论。
TIME_WAIT状态
上面说了,客户端在收到服务器结束报文段之后,并没有直接进入CLOSED状态,而是转移到TIME_WAIT状态。在这个状态,客户端连接要等待一段2MSL(Maximum Segment Life,报文段最大生存时间)的时间,才能完全关闭,对于MSL,RFC 1122的建议值是2min。
TIME_WAIT状态存在的原因有两点:
可靠地终止TCP连接
假设用于确认服务器结束报文段的确认报文丢失,那么服务器讲重发结束报文段。因此客户端需要停留在一个状态来处理重复收到的结束报文段。否则,客户端将以复位报文段回应服务器,服务器则认为这是一个错误,因为它期望的是一个确认报文段。
保证让迟到的TCP报文段有足够的时间被识别并丢弃
一个TCP端口不能被同时打开多次(两次及以上)。当一个TCP连接处于TIME_WAIT状态时,将无法立即使用该连接占用的端口来建立一个新连接。反过来思考,如果不存在TIME_WAIT状态,则可以立即建立一个与刚才连接有相同IP以及端口号的连接,这样的新连接可能收到原来连接迟到的报文段,而这显然是不应该发生的。
复位报文段
在某些特殊条件下,TCP连接的一端会向另一端发送携带RST标志的报文段,即复位报文段,以通知对方关闭连接或重新建立连接。这里讨论复位报文段的3种情况。
访问不存在的端口
当客户端程序访问一个不存在的端口时,目标主机将给它发送一个复位报文段。
其实,当服务器某个端口仍被处于TIME_WAIT状态的连接所占用时,客户端程序也将收到复位报文段。
异常终止连接
之前讨论的都是正常的终止方式,即:数据交换完成之后,一方给另一方发送结束报文段。
TCP提供了异常终止一个连接的方法,给对方发送一个复位报文段。一旦发送该复位报文段,发送端所有排队等待发送的数据都将被丢弃。
应用程序可以适用socket选项SO_LINGER来发送复位报文段,以异常终止一个连接。
处理半打开连接
假设服务器与客户端的某一方为A,另一方为B。
A关闭或者异常终止了连接,而对方没有接收到结束报文段,此时,B仍然维持着原来的连接,A即使重启也没有该连接的任何信息了。这种状态称为半打开状态。
若B往处于半打开状态的连接写入数据,则A将回应一个复位报文段。
TCP的数据流
TCP报文段所携带的应用程序数据按照长度分为两种:交互数据 和 成块数据。
交互数据仅包含很少的字节。使用交互数据的应用程序(或协议)对实时性要求高,比如telnet、ssh等。
成块数据其长度通常为TCP报文段允许的最大数据长度(即MSS)。使用成块数据的应用程序(或协议)对传输效率要求高,比如ftp。
在这一节,先讨论交互数据流。
TCP交互数据流
通常是一些携带ACK标志的报文段。携带交互数据的微小TCP报文段数量一般很多(一个按键输入就导致一个TCP报文段,见47页例子)。
服务器的延迟确认:即服务器不马上确认上次收到的数据,而是在一端延迟时间后查看本端是否有数据需要发送,如果有,则和确认信息一起发出。因为服务器对客户请求处理得很快,所以它发送确认报文段时总是有数据一起发送。这样可以减少发送TCP报文段的数量。
交互数据流在广域网上可能存在很大的延迟,导致拥塞发生。解决的一个简单有效的方法是使用Nagle算法。
Nagle算法要求一个TCP连接的通信双方在任意时刻都最多只能发送一个未被确认的TCP报文段,在该TCP报文段的确认到达之前不能发送其他TCP报文段。 另一方面,发送方在等待确认的同时收集本端需要发送的微量数据,并在确认到来时以一个TCP报文段将它们全部发出。
这样就极大地减少了网络上的微小TCP报文段的数量。该算法的另一个优点在于其自适应性:确认到达得越快,数据也就发送得越快。
TCP成块数据流
考虑用FTP协议传输一个大文件。发送方会连续发送多个TCP报文段,接收方可以一次确认所有这些报文段。
而发送方在收到上一次确认之后,还能继续发送多少个报文段呢?
这是由接收通告窗口(还需要考虑拥塞窗口)的大小决定的。如,报文段中win为30084,窗口扩大因子为6,则表示客户端还能接收30084*64字节,按每个报文段长度16384字节来算,发送方还能继续发送的报文段数量为 30084*64/16384即106个。
带外数据
有些传输层协议具有带外(Out of Band, OOB)数据的概念。用于迅速通告对方本端发生的重要事件。
带外数据的传输有两种方式:
- 使用一条独立的传输层连接
- 映射到传输普通数据的连接中
因此,带外数据比普通数据(也称带内数据)有更高的优先级,它应该立即被发送,而不论发送缓冲区中是否有派对等待发送的普通数据。不过,实际应用中,带外数据的使用很少见。
UDP没有实现带外数据传输,TCP也没有真正的带外数据。不过,TCP利用其头部的紧急指针标志和紧急指针两个字段,给应用程序提供了一种紧急方式,该方式利用传输普通数据的连接来传输带外数据。这种紧急数据的含义和带外数据类似(因此后文将TCP紧急数据称为带外数据)。
当TCP向连接中发送带外数据时,会将含带外数据的报文段头部设置URG标志,并且紧急指针被设置为指向最后一个带外数据的下一字节(多字节的带外数据中只有最后一个字节被当作带外数据,因为接收端的带外缓冲只有1个字节,并且上层应用没有及时将带外数据从带外缓存中读出,后续的带外数据将覆盖它)。
TCP超时重传
在剩下的两节中,讨论异常网络状况下(开始出现超时或丢包),TCP如果控制数据传输以保证其承诺的可靠服务。
对于超时,TCP模块为每个TCP报文段维护一个重传定时器,该定时器在TCP报文段第一次被发送时启动。如果超时时间内未收到接收方的确认应答,TCP模块将重传TCP报文段并重置定时器。
至于下次重传的超时时间如何选择,以及最多执行多少次重传,就是TCP的重传策略。
Linux下TCP的超时重传策略为:每次重传后,超时时间都增加一倍。
在所有重传均失败的情况下,底层的IP和ARP开始接管,直到客户端放弃连接为止。
Linux中有两个重要的内核参数与TCP超时重传相关:
/proc/sys/net/ipv4/tcp_retries1:指定底层IP接管之前TCP最少执行的重传次数,默认值是3。
``/proc/sys/net/ipv4/tcp_retries2`:指连接放弃前TCP最多可以执行的重传次数,默认值是15。
虽然超时会导致TCP报文段重传,但TCP报文段的重传可以发生在超时之前,即快速重传,在下一节讨论。
TCP拥塞控制
TCP模块还有一个重要的任务,就是提高网络利用率,降低丢包率,并保证网络资源对每条数据流的公平性。这就是所谓的拥塞控制(详见RFC 5681)。
拥塞控制包括四个部分:
- 慢启动(slow start)
- 拥塞避免(congestion avoidance)
- 快速重传(fast retransmit)
- 快速恢复(fast recovery)
Linux下对拥塞算法有多种实现,如reno算法,vegas算法和cubic算法等。它们或部分或全部实现了上述的四个部分。/proc/sys/net/ipv4/tcp_congestion_control文件指示了机器当前所使用的拥塞控制算法。
拥塞控制的最终受控变量是
发送窗口(Send Window,SWND),即发送端向网络一次连续写入(收到其中第一个数据的确认之前)的数据量或TCP报文段数量。
这些TCP报文段的最大长度(仅指数据部分)称为SMSS(Sender MSS,发送者最大段大小),其值一般等于MSS。
发送端需要合理地选择SWND的大小。若SWND太小,会引起明显的网络延迟;反之,如果SWND太大,则容易导致网络拥塞。前文提到,在TCP头部中的接收通告窗口(RWND)可以控制发送端的传输速度,同时,发送端也引入了一个称为拥塞窗口(Congestion Window, CWND)的状态变量来控制SWND。实际的SWND值是RWND和CWND中的较小者。
慢启动和拥塞避免
TCP连接建立好之后,CWND将被设置成初始值IW(Initial Window),其大小为2~4个SMSS。但新的Linux内核提高了该初始值,以减小传输延迟。此后,发送端每收到接收端的一个确认,其CWND就按下面公式增加:
$$
CWND+=min(N,SMSS) 【3.1】
$$
其中,N是此次确认中包含的之前未被确认的字节数。
这样,CWND将按照指数形式扩大,这就是所谓的慢启动。其理由是,TCP模块刚开始发送数据时并不知道网络的实际情况,需要用一种试探的方式平滑地增加CWND的大小。
但如果不施加其他手段,慢启动必然使CWND很快膨胀(可见慢启动其实不慢),并最终导致网络拥塞。因此,TCP拥塞控制中定义了一个重要的状态变量:慢启动门限(slow start threshold size, ssthresh)。当CWND大小超过该值时,TCP拥塞控制将进入拥塞避免阶段。
拥塞避免算法使得CWND按照线性方式增加,从而减缓其扩大。RFC 5681中提到两种实现方式:
每个RTT时间内按照公式3.1计算新的CWND,而不管该RTT时间内发送端收到多少个确认。
每收到一个对新数据的确认报文段,就按照公式3.2来更新CWND。
$$
CWND+=SMSS*SMSS/CWND【3.2】
$$
以上,讨论了发送端在未检测到拥塞时所采用的积极避免拥塞的方法。接下来介绍拥塞发生时拥塞控制的行为。不过,首先需要弄明白发送端如何判断拥塞已经发生。发送端判断依据有如下两个:
- 传输超时,或者说TCP重传定时器溢出
- 接收到重复的确认报文段
第一种情况仍使用慢启动和拥塞避免。将进行重传,并做如下调整:
$$
ssthresh=max(FlightSize/2,2*SMSS)【3.3】
$$
$$
CWND<=SMSS
$$
其中FlightSize是已经发送但未收到确认的字节数。这样调整之后,CWND将小于SMSS,也必然小于新的慢启动门限值ssthresh。
对第二中情况则使用快速重传和快速恢复。
快速重传和快速恢复
很多情况下,发送端都可能接收到重复的确认报文段,比如TCP报文段丢失,或者接收端收到乱序TCP报文段并重排等。
拥塞控制算法需要判断当收到重复的确认报文段时,网络是否真的发生了拥塞。具体做法是:发送端如果连续收到3个重复的确认报文段,就认为是拥塞发生了。然后使用快速重传和快速恢复算法来处理拥塞,具体过程如下:
当收到第三个重复的确认报文段时,按公式3.3计算
ssthresh,然后立即重传丢失的报文段,并按照公式3.4设置CWND。
$$
CWND=ssthresh+3*SMSS【3.4】
$$每次收到1个重复的确认时,设置CWND=CWND+SMSS。此时发送端可以发送新的TCP报文段。
当收到新数据的确认时,设置CWND=ssthresh。
快速重传和快速恢复完成之后,拥塞控制将恢复到拥塞避免阶段。
TCP/IP通信案例:访问Internet上的Web服务器
由于本章内容叙述上不方便,就不全放到博客中了,挑一些关键的知识点来说。
代理服务器
在HTTP通信链上,客户端和目标服务器之间通常存在某种中转代理服务器,他们提供对目标资源的中转访问。代理服务器按照其使用方式和作用,分为正向代理服务器、反向代理服务器和透明代理服务器。
- 正向代理:要求客户端自己设置代理服务器的地址。客户的每次请求都将直接发送到该服务器,并由代理服务器来请求目标资源。
- 反向代理:被设置在服务器端,客户端无需进行任何设置。代理服务器来接收Internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从内部服务器上得到的结果返回给客户端。
- 透明代理只能设置在网关上。透明代理可以看成正向代理的一种特殊情况。
代理服务器通常还提供缓存目标资源的功能。优秀的开源软件squid、varnish都是提供了缓存能力的代理服务器软件,其中squid支持所有代理方式,而varnish仅能用作反向代理。
可以用service脚本程序启动服务器程序,如:
1 | $ sudo service squid3 restart |
service是一个脚本程序(/usr/sbin/service),它为 /etc/init.d 目录下的众多服务器程序(如httpd、vsftpd、sshd和mysqld等)的启动(start)、停止(stop)和重启(restart)等动作提供了统一的管理。
本地名称查询
一般来说,通过域名访问Internet上的某台主机时,需要使用DNS服务来获取该主机的IP地址。但如果我们通过主机名来访问本地局域网上的机器,则可以通过本地静态文件来获得该机器的IP地址。
Linux将目标主机名及其对应IP地址存储在/etc/hosts配置文件中。当需要查询某个主机名对应的IP地址时,程序将首先检查这个文件。如果程序在/etc/hosts文件中未找到目标机器名对应的IP地址,将求助于DNS服务。
深入解析高性能服务器编程
Linux网络编程基础API
本章是承前启后的一章,从三个方面讨论Linux网络API:
- socket地址API。socket最开始的含义是一个IP地址和端口对(ip, port)。它唯一地表示了使用TCP通信的一端。
- socket基础API。socket的主要API都定义在
sys/socket.h头文件中,包括创建、命名、监听、接收连接、发起连接、读写数据、获取地址信息、检测带外标记,以及读取和设置socket选项。 - 网络信息API。Linux提供了一套网络信息API,以实现主机名和IP地址之间的转换,以及服务名称和端口号之间的转换。这些API都定义在netdb.h头文件中。
所谓socket(套接字),就是对网络中不同主机上的应用程序之间进行双向通信的端点的抽象。一个socket就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制。socket上联应用程序,下联网络协议栈,是应用程序通过网络协议进行通信的接口。
socket地址API
要学习socket地址API,要先理解主机字节序和网络字节序。
主机字节序和网络字节序
字节序,是指多字节数据在计算机内存中存储或者网络传输时各字节的存储顺序。
字节序分为小端字节序(little endian)和大端字节序(big endian)。
小端字节序:将低位字节存储在低地址处。
大端字节序:将高位字节存储在低地址处。
比如,内存中的两个字0x01020304的存储方式(&4000~$40003是地址单元):
| &4000 | &4001 | &4002 | &4003 | |
|---|---|---|---|---|
| 小端字节序 | 04 | 03 | 02 | 01 |
| 大端字节序 | 01 | 02 | 03 | 04 |
下面的代码可以检查机器的字节序:
1 |
|
现代PC大多采用小端字节序,因此小端字节序又被称为主机字节序。
现在我们来假设,数据在两台使用不同字节序的主机之间进行传输,可想而知,接收端必然会错误地解释数据。而解决的方法是:协商一个在网络中传输时使用的字节序。这样,接收端知道对方传过来的总是特定字节序的数据,而再根据自身采用的字节序来决定是否需要进行转换(不同则转,相同不转)。我们将大端字节序协商为网络传输中使用的字节序,因此,大端字节序也称为网络字节序。
Linux提供了如下4个函数来完成主机字节序和网络字节序之间的转换:
1 |
|
比如”htonl”表示“host to network long”。长整型函数通常用来转换IP地址,短整型函数通常用来转换端口号。
通用socket地址
socket网络编程接口中表示socket地址的是结构体sockaddr,其定义如下:
1 |
|
sa_family是地址族类型(sa_family_t)的变量。地址族类型通常与协议族类型对应:
| 协议族 | 地址族 | 描述 |
|---|---|---|
| PF_UNIX | AF_UNIX | UNIX本地域协议族 |
| PF_INET | AF_INET | TCP/IPv4协议族 |
| PF_INET6 | AF_INET6 | TCP/IPv6协议族 |
宏PF_*和AF_*都定义在bits/socket.h头文件中,且后者与前者有完全相同的值,所以二者通常混用。
sa_data用于存放socket地址值。但是,不同的协议族的地址值具有不同的含义和长度,如下表所示:
| 协议族 | 地址值含义和长度 |
|---|---|
| PF_UNIX | 文件的路径名,长度可达108字节 |
| PF_INET | 16bit端口号和32bit IPv4地址,共6字节 |
| PF_INET6 | 16bit端口号,32bit流表示,128bit IPv6地址,32bit范围ID,共26字节 |
由表可见,14字节的sa_data根本无法完全容纳多数协议族的地址值。因此,Linux定义了下面这个新的通用socket地址结构体:
1 |
|
这个结构体不仅提供了足够大的空间用于存放地址值,而且是内存对齐的。
专用socket地址
上面两个通用socket地址结构体显然很不好用,比如设置与获取IP地址和端口号就需要执行繁琐的位操作。因此,Linux为各个协议族提供了专门的socket地址结构体。
UNIX本地域协议使用的专用socket地址结构体:sockaddr_un
1 |
|
TCP/IP协议族有sockadrr_in和sockaddr_in6两个专用socket地址结构体,分别于IPv4和IPv6:
1 | // sockaddr_in 在#include<netinet/in.h>或#include<arpa/inet.h>中定义 |
1 | struct sockaddr_in6 |
需要特别注意:
所有专用socket地址(以及sockaddr_storage)类型的变量在实际使用时都需要转化为通用socket地址类型sockaddr(强制转换即可),因为所有socket编程接口使用的地址参数的类型都是sockaddr。
IP地址转换函数
通常,我们习惯用字符串来表示IP地址,如点分十进制表示IPv4地址,十六进制表示IPv6地址。但在编程中,需要将它们转化为整数才能使用,而记录日志时,却又要转化为可读的字符串。下面,提供了3个函数用于 点分十进制字符串表示的IPv4地址 和 用网络字节序整数表示的IPv4地址 之间的转换:
1 |
|
in_addr_t函数将点分十进制字符串表示的IPv4地址转化为用网络字节序整数表示的IPv4地址。它失败将返回INADDR_NONE。
inet_aton函数完成和inet_addr同样的功能,但是将转化结果存储于参数inp指向的地址结构中。它成功返回1,失败返回0。
inet_ntoa函数将用网络字节序整数表示的IPv4地址转化为用淀粉十进制字符串表示的IPv4地址。但是,需要注意,该函数内部用一个静态变量存储转化结果,函数的返回值指向该静态内存,因此inet_ntoa是不可重入的。下面代码揭示了其不可重入性:
1 | char* szValue1 = inet_ntoa(“1.2.3.4”); |
得到的结果是,address1和address2都是10.194.71.60。
下面还有一对函数也能完成和前面3个函数同样的功能,并且还同时适用于IPv4和IPv6地址:
1 |
|
af用于指定地址族,可以是AF_INET或者是AF_INET6。inet_pton成功返回1,失败返回0并设置errno。
inet_ntop进行相反的转换,其中最后一个参数cnt指定目标存储单元的大小。成功返回目标存储单元的地址,失败返回NULL并设置errno。下面两个宏能帮助我们指定这个大小:
1 |
创建socket
socket就是可读、可写、可控制、可关闭的文件描述符。下面的系统调用可以创建一个socket:
1 |
|
domain参数告诉系统应该适用哪个底层协议族(PF_INET,PF_INET6或PF_UNIX等)。
type参数指定服务类型。服务类型主要有SOCK_STREAM(流服务,表示传输层用TCP协议)以及SOCK_DGRAM(数据报服务,表示传输层用UDP协议)。
值得注意,自Linux内核版本2.6.17起,type参数可以接受上述服务类型与下面两个重要标志相与的值:SOCK_NONBLOCK和SOCK_CLOEXEC。它们分别表示,将新创建的socket设为非阻塞的,以及用fork调用创建子进程时在子进程中关闭该socket。
protocol参数是在前两个参数构成的协议集合下,再选择一个具体的协议。不过这个值通常是唯一的(前两个参数已经完全决定了它)。几乎在所有情况下,都将它设置为0,表示使用默认协议。
socket系统调用成功时返回一个socket文件描述符,失败则返回-1并设置errno。
命名socket
创建socket时,指定了地址族,但是并未指定使用该地址族中的哪个具体socket地址。将一个socket与socket地址绑定称为给socket命名。
服务器程序中,通常要命名socket,只有这样客户端才知道该如何连接它。客户端则不需要命名socket,而是采用匿名的方式,即使用操作系统自动分配的socket地址。命名socket的系统调用是bind,其定义如下:
1 |
|
bind将my_addr所指的socket地址分配给未命名的sockfd文件描述符,addrlen参数指定该socket地址的长度。bind成功时返回0,失败则返回-1并设置errno。其中常见的两种errno含义如下:
- EACCES,被绑定的地址是受保护的地址,仅超级用户能够访问。如普通用户将socket绑定到知名服务端口(端口号为0~1023)上时。
- EADDRINUSE,被绑定的地址正在使用中。比如将socket绑定到一个处于TIME_WAIT状态的socket地址。
监听socket
socket被命名之后,还不能马上接受客户连接,需要使用如下的系统调用来创建一个监听队列,以存放待处理的客户连接:
1 |
|
sockfd参数指定被监听的socket。
backlog参数指定内核监听队列的最大长度。典型值是5,不过监听队列中完整连接的上限通常比backlog值略大。
自linux内核2.2之后,backlog参数表示只处于完全连接状态(ESTABLISHED)socket的上限。
监听队列的长度如果超过backlog,服务器将不受理新的客户连接,客户端也将收到ECONNREFUSED错误信息。
listen调用成功时返回0,失败则返回-1并设置errno。
下面编写一个服务器程序,以研究backlog参数对listen系统调用的实际影响。
1 |
|
关于signal函数的用法,可参考:https://www.runoob.com/cprogramming/c-function-signal.html
我通过vmware建立了两台处于同一局域网的ubuntu主机,一台作为服务器(192.168.141.137),另一台作为客户端(192.168.141.139)。以此来作为测试。
1 | # 服务器编译运行代码 |

这里的截图显示已经运行成功了,而监听队列最多就存在6(backlog+1)个ESTABLISHED状态的连接。
接受连接
accept系统调用能够从listen监听队列中接受一个连接:
1 |
|
sockfd参数是执行过listen系统调用的监听socket。
addr参数用来获取被接受连接的远端socket地址(创建一个空的结构体,由accetp函数进行填充),该socket地址的长度由addrlen参数指出。(addrlen在调用时设置为addr指向区域的大小,而调用结束时被设置为实际地址信息的长度,在函数调用过程中需要改变,所以要指针)
accept调用成功时返回一个新的连接socket,该socket唯一地标识了被接受的这个连接,服务器可通过读写该socket来与连接对应的客户端通信。失败则返回-1并设置errno。
我们编写如下代码,并考虑处于ESTABLISHED连接的客户端出现网络异常,或者提前退出时,服务器的accept调用是否成功。
1 |
|
接下来我将在网络中【服务器IP:192.168.141.137,客户端IP:192.168.141.139】进行测试该代码:
1 | # 服务器中编译运行程序 |
得到的测试结果如下:

可以发现accept调用能够正常返回,并输出客户端的IP与连接端口号。由此可见,accept只是从监听队列中取出连接,而不论连接处于何种状态,更不关心任何网络状况的变化。
同时,该程序结束后,我们马上重新执行程序会出错,使用netstat查看网络状况,可以看到刚刚的连接处于TIME_WAIT状态。这是TCP连接刚断开后进入的状态,等待2*MSL的时间,就恢复正常了。
发起连接
服务器通过listen调用来被动接受连接,而客户端需要通过如下系统调用来主动与服务器建立连接:
1 |
|
sockfd参数是由客户端socket系统调用返回的一个socket。
serv_addr参数是服务器监听的socket地址,addrlen参数则指定这个地址的长度。
connect成功时返回0。一旦成功建立连接,sockfd就唯一标识了这个连接,客户端就可以通过读写sockfd来与服务器通信。失败则返回-1并设置errno。常见的两种errno含义如下:
- ECONNREFUSED,目标端口不存在,连接被拒绝。
- ETIMEDOUT,连接超时。
关闭连接
关闭一个连接实际上就是关闭该连接对应的socket,可以通过关闭普通文件描述符的系统调用来完成:
1 |
|
fd参数是待关闭的socket。
不过,close系统调用并非总是立即关闭一个连接,而是将fd的引用计数减1。只有当fd的引用计数为0时,才真正关闭连接。在多进程程序中,一次fork系统调用默认将使父进程中打开的socket的引用计数加1,因此我们必须在父进程和子进程中都对该socket执行close调用才能将连接关闭。
如果无论如何都要立即终止连接(而不是将socket的引用计数减1),可以使用shutdown系统调用(相对于close来说,它是专门为网络编程设计的)。
1 |
|
sockfd参数是待关闭的socket。
howto参数决定了shutdown的行为,可以取下表中的某个值:
| 可选值 | 含义 |
|---|---|
| SHUT_RD | 关闭sockfd上读的一半。应用程序不能再针对socket文件描述符执行读操作,并且该socket接收缓冲区中的数据都将被丢弃。 |
| SHUT_WR | 关闭sockfd上写的一半。sockfd的发送缓冲区中的数据会在真正关闭连接之前全部发送出去,应用程序不可再对该socket文件描述符执行写操作。这种情况下,处于半关闭状态。 |
| SHUT_RDWR | 同时关闭sockfd上的读和写 |
由此可见,shutdown能够分别关闭socket上的读或写,或者都关闭。而close再关闭连接时只能将读写都关闭。
shutdown调用成功时返回0,失败则返回-1并设置errno。
数据读写
TCP数据读写
对文件的读写操作(read和write)同样适用于socket。但是socket编程接口提供了几个专门用于socket数据读写的系统调用,它们增加了对数据读写的控制。其中用于TCP流数据读写的系统调用是:
1 |
|
recv读取sockfd上的数据,buf和len参数分别指定读缓冲区的位置和大小,flags参数的含义见后文,通常设置为0即可。 recv调用成功时返回实际读取到的数据的长度,它可能小于我们期望的长度(len)。因此可能要多次调用recv,才能读取到完整的数据。 【注意,recv可能返回0,这意味着通信对方已经关闭连接了】。recv出错时返回-1并设置errno。
send往sockfd上写入数据,buf和len参数分别指定写缓冲区的位置和大小。send成功时返回实际写入的数据的长度,失败则返回-1并设置errno。
flags参数为数据收发提供了额外的控制,它可以取下表选项中的一个或者多个的逻辑或。
| 选项名 | 含义 | send | recv |
|---|---|---|---|
| MSG_CONFIRM | 指示数据链路层协议将持续监听对方的回应,直到得到答复。它仅能用于SOCK_DGRAM和SOCK_RAW类型的socket | Y | N |
| MSG_DONTROUTE | 不查看路由表,直接将数据发送给本地局域网络内的主机。这表示发送者确切地知道目标主机就在本地网络上 | Y | N |
| MSG_DONTWAIT | 对socket的此次操作将会是非阻塞的 | Y | Y |
| MSG_MORE | 告诉内核应用程序还有更多数据要发送,内核将超时等待新数据写入TCP发送缓冲区后一并发送。这样可防止TCP发送过多小的报文段,从而提高传输效率。 | Y | N |
| MSG_WAITALL | 读操作仅在读取到指定数量的字节后才返回 | N | Y |
| MSG_PEEK | 窥探读缓存中的数据,此次读操作不会导致这些数据被清除 | N | Y |
| MSG_OOB | 发送或接收紧急数据 | Y | Y |
| MSG_NOSIGNAL | 往读端关闭的管道或者socket连接中写数据时不引发SIGPIPE信号 | Y | N |
接下来来举例如何使用这些选项。MSG_OOB选项给应用程序提供了发送和接收带外数据的方法,发送端和接收端代码如下:
发送端:发送带外数据【客户端执行】<testoobsend.c>
1 |
|
接收端:接收带外数据【服务端执行】<testoobrecv.c>
1 |
|
我们用之前的网络来进行测试,首先在服务器(192.168.141.137)上启动服务器程序(testoobrecv),然后到客户端(192.168.141.139)上执行客户端程序(testoobsend),具体如下:
1 | # 服务器执行 |
得到服务器的输出:

由此可见,客户端发送给服务器的3字节带外数据“abc”中,仅有最后一个字符“c”被服务器当成真正的带外数据接收(如上一章TCP带外数据的一节中所述,即带外缓冲区只有一个字节)。并且,服务器对正常数据的接收将被带外数据截断,即前一部分正常数据“123ab”和后续的正常数据“123”是不能被一个recv调用全部读出的。
值得一提的是,flags参数只对send和recv的当前调用生效,而后面我们将看到如何通过setsockopt系统调用永久性地修改socket的某些属性。
UDP数据读写
socket编程接口中用于UDP数据读写的系统调用是:
1 |
|
recvfrom读取sockfd上的数据,buf和len参数分别指定读缓冲区的位置和大小。【因为UDP通信没有连接的概念】,所以我们每次读取数据都需要获取发送端的socket地址,即参数src_addr所指内容,addrlen参数则指定该地址的长度。
sendto往sockfd上写入数据,buf和len参数分别指定写缓冲区的位置和大小。dest_addr参数指定接收端的socket地址,addrlen参数则指定该地址的长度。
这两个系统调用的flags参数以及返回值的含义均与send/recv系统调用的flags参数及返回值相同。
值得一提的是,recvfrom/sendto系统调用也可以用于面向连接(STREAM)的socket的数据读写,只需要把最后两个参数都设置为NULL以忽略发送端/接收端的socket地址就可以了(因为面向连接已经与对方建立了连接,socket地址已知)。
通用数据读写函数
socket编程接口还提供了一对通用的数据读写系统调用。它们不仅能用于TCP流数据,也能用于UDP数据报:
1 |
|
sockfd参数指定被操作的目标socket。
msg参数是msghdr结构体类型的指针,msghdr结构体定义如下:
1 | struct msghdr |
msg_name成员指向一个socket地址结构变量。它指定通信对方的socket地址(对于面向连接的TCP协议,该成员必须被设置为NULL,因为对方socket已知)。msg_namelen成员则指定了msg_name所指socket地址的长度。
msg_iov成员是iovec结构体类型的指针,其定义如下:
1 | struct iovec |
iovec结构体封装了一块内存的起始地址和长度。
msg_iovlen则指定这样的iovec结构对象有多少个。
对于
recvmsg而言,数据将被读取并存在msg_iovlen块分散的内存中,这些内存的位置和长度由msg_iov指向的数组指定,这称为分散读(scatter read)。对于
sendmsg而言,msg_iovlen块分散内存中的数据将被一并发送,这称为集中写(gather write)。
msg_control和msg_controllen成员用于辅助数据的传送。我们将在后面介绍如何使用它们来实现进程间传递文件描述符。
msg_flags成员无须设定,会复制函数中的flags参数内容。recvmsg还会在调用结束前,将某些更新后的标志设置到msg_flags中。flags参数与send/recv的flags参数以及返回值相同。
带外标记
在“TCP数据读写”中演示了TCP带外数据的接收方法。但是在实际应用中,无法预期带外数据何时到来。而这一点可以通过sockatmark系统调用来检测紧急标志:
1 |
|
sockatmark判断sockfd是否处于带外标记,即下一个被读取到的数据是否是带外数据。如果是,sockatmark返回1,此时就可以利用带MSG_OOB标志的recv调用来接收带外数据。如果不是,则sockatmark返回0。
Linux内核检测到TCP紧急标志时,将通知应用程序有带外数据需要接收。内核通知应用程序带外数据到达的两种常见方法是:I/O复用产生的异常事件 和 SIGURG信号。
地址信息函数
若想知道一个连接socket的本端socket地址,以及远端的socket地址。下面两个函数可以解决这个问题:
1 |
|
getsockname获取sockfd对应的本端socket地址,并将其存储于address参数指定的内存中,该地址的长度存储于address_len参数指向的变量中。如果实际socket地址的长度大于address所指内存区的大小,那么该socket地址将被截断。getsockname成功时返回0,失败返回-1并设置errno。
getpeername获取sockfd对应的远端socket地址,其参数及返回值含义与getsockname相同。
socket选项
fcntl系统调用是控制文件描述符属性的通用POSIX方法,而下面两个系统调用则是专门用来读取和设置socket文件描述符属性的方法:
1 |
|
sockfd参数指定被操作的目标socket。
level参数指定要操作哪个协议的选项,比如IPv4、IPv6、TCP等。
option_name参数则指定选项的名字。option_value和option_len参数分别是被操作选项的值和长度,不同的选项具有不同类型的值。
getsockopt和setsockopt两个函数成功时返回0,失败时返回-1并设置errno。
下面列出一些常用的socket选项:

值得一提,有部分socket选项只能在调用listen系统调用前针对监听socket设置才有效。这是因为连接socket只能由accept调用返回,而accept从listen监听队列中接受的连接至少已经完成了TCP三次握手的前两个步骤(连接至少进入SYN_RCVD状态),这说明接受连接上发送出了TCP同步报文段。但有的socket选项却应该在TCP同步报文段中设置,比如TCP最大报文段选项。
对于这种情况,Linux提供的解决方案是:对监听socket设置这些socket选项,那么accept返回的连接socket将自动继承这些选项。这些socket选项包括:SO_DEBUG, SO_DONTROUTE, SO_KEEPALIVE, SO_LINGER, SO_OOBINLINE, SO_RCVBUF, SO_RCVLOWAT, SO_SNDBUF, SO_SNDLOWAT, TCP_MAXSEG和TCP_NODELAY。
而对于客户端来说,这些socket选项需要在connect函数执行前设置,因为connect调用成功之后,TCP三次握手已经完成。
下面来详细讨论部分重要的socket选项:
SO_REUSEADDR:服务器程序可以通过SO_REUSEADDR选项来强制使用被处于TIME_WAIT状态的连接占用的socket地址。SO_RCVBUF和SO_SNDBUF:分别表示TCP接收缓冲区和发送缓冲区的大小。当用setsockopt来设置TCP的接收缓冲区和发送缓冲区大小时,系统都会将其值加倍,并且不得小于某个最小值。(TCP接收缓冲区最小值是256字节,发送缓冲区最小值是2048字节)SO_RCVLOWAT和SO_SNDLOWAT:分别表示TCP接收缓冲区和发送缓冲区的低水位标记。它们一般被I/O复用系统调用用来判断socket是否可读或可写。当TCP接收缓冲区中可读数据总数大于其低水位标记时,I/O复用系统调用将通知应用程序可从对应的socket上读取数据;当TCP发送缓冲区中的空闲空间大于其低水位标记时,通知应用程序可在对应socket上写入数据。SO_LINGER:该选项用于控制close系统调用在关闭TCP连接时的行为。默认情况下,使用close系统调用来关闭一个socket时,close将立即返回,TCP模块负责把该socket对应的TCP发送缓冲区中残留的数据发送给对方。在设置(获取)SO_LINGER选项的值时,需要给系统调用传递一个linger类型的结构体,其定义如下:
1
2
3
4
5
6
strcut linger
{
int l_onoff; /* 开启(非0)还是关闭(0)该选项 */
int l_linger; /* 滞留时间 */
};根据linger结构体中两个成员变量的不同值,close系统调用可能产生如下3种行为之一:
- l_onoff等于0:close用默认行为来关闭socket
- l_onoff不为0,l_linger等于0:此时close系统调用立即返回,TCP模块将丢弃被关闭的socket对应的TCP发送缓冲区中残留的数据,同时给对方发送一个复位报文段。这种情况给服务器提供了异常终止一个连接的方法。
- l_onoff不为0,l_linger大于0:此时close的行为取决于两个条件:(1)被关闭的socket对应的TCP发送缓冲区中是否还有残留的数据;(2)该socket是阻塞的还是非阻塞的。
网络信息API
socket地址的两个要素:IP地址和端口号,都是用数值表示的。这不便于记忆,也不便于扩展(从IPv4转移到IPv6)。可以通过网络信息API,用主机名代替IP地址,用服务名称来代替端口号,如下面的例子:
1 | telnet 127.0.0.1 80 |
这两条telnet命令具有完全相同的作用(telnet客户端通过网络信息API实现了主机名到IP地址,服务名称到端口号的转换)。
gethostbyname和gethostbyaddr
gethostbyname函数根据主机名称获取主机的完整信息,通常先在本地的/etc/hosts配置文件中查找主机,如果没有找到,再去访问DNS服务器。而gethostbyaddr函数根据IP地址获取主机完整信息。两个函数的定义如下:
1 |
|
name参数指定目标主机的主机名。
addr参数指定目标主机的IP地址,len参数指定所指IP地址的长度,type参数指定addr所指IP地址的类型(AF_INET和AF_INET6)。
两个函数返回的都是hostent结构体类型的指针,该结构体的定义如下:
1 |
|
getservbyname和getservbyport
getservbyname函数根据服务名称获取某个服务的完整信息,getservbyport函数根据端口号获取某个服务的完整信息。他们实际上都是通过读取/etc/services文件来获取服务的信息的。这两个函数的定义如下:
1 |
|
name参数指定目标服务的名称。
port参数指定目标服务对应的端口号。
proto参数指定服务类型,可选参数:(1)“tcp”,表示获取流服务;(2)“udp”,表示获取数据报服务;(3)NULL,表示获取所有类型的服务。
这两个函数返回的都是servent结构体类型的指针,其定义如下:
1 |
|
特别注意:以上四个函数都是不可重入的,即非线程安全的。
不过netdb.h头文件给出了它们的可重入版本。正如Linux下所有其他函数的可重入版本的命名规则那样,这些函数的函数名是在原函数名尾部加上_r (re-entrant)。
接下来,我们通过主机名和服务名来访问服务器上的daytime服务,以获取该机器的系统时间。
先启动服务器(192.168.141.137)上的daytime服务并进行本地测试:
1 | $ sudo vim /etc/xinetd.d/daytime |
再在客户端(192.168.141.139)上为服务器配置一个主机名,到hosts文件中配置:
1 | $ sudo vim /etc/hosts |
在客户端编写代码:
1 |
|
客户端中编译运行代码:
1 | $ gcc testconndaytime.c -o testconndaytime |
得到的输出如下:

getaddrinfo
该函数既能通过主机名获得IP地址(内部使用gethostbyname),也可以通过服务名获得端口号(内部使用getservbyname)。该函数定义如下:
1 |
|
hostname参数可以接收主机名,也可以接收字符串表示的IP地址。
service参数可以接收服务名,也可以接收字符串表示的十进制端口号。
hints参数是应用程序给getaddrinfo的一个提示,以对其输出进行更精确的控制。可以设置为NULL,表示允许函数反馈任何可用的结果。
result参数指向一个链表,该链表用于存储函数反馈的结果。能够被隐式地分配堆内存,所以getaddrinfo调用结束后,必须使用如下配对函数来释放这块内存:
1 |
|
addrinfo结构体定义如下:
1 | struct addrinfo |
当使用hints参数时,可以设置其ai_flags, ai_family, ai_socktype和ai_protocol四个字段,其他字段则必须被设置为NULL。
getnameinfo
该函数能通过socket地址同时获得以字符串表示的主机名(内部使用gethostbyaddr),和服务名(内部使用getservbyport)。该函数定义如下:
1 |
|
9月8日,今天把最“苦”的任务顺利完结了,然而没有更多的时间留给linux学习,今天便稍作复习。加油(ง •_•)ง
高级I/O函数
Linux提供了很多高级的I/O函数。它们并不像Linux基础I/O函数那么常用,但是在特定的条件下却表现出优秀的性能。本章讨论其中和网络编程相关的几个,这些函数大致分为三类:
- 用于创建文件描述符的函数,包括 pipe、dup/dup2 函数。
- 用于读写数据的函数,包括readv/writev、sendfile、mmap/munmap、splice和tee函数。
- 用于控制I/O行为和属性的函数,包括fcntl函数。
pipe函数
pipe函数可用于创建一个管道,以实现进程间通信。其定义如下:
1 |
|
fd参数是一个包含两个int型整数的数组指针。
pipe函数成功时返回0,并将一对打开的文件描述符值填入其参数指向的数组。如果失败,则返回-1并设置errno。
通过pipe函数创建的这两个文件描述符fd[0]和fd[1]分别构成管道的两端,并且,fd[0]只能用于从管道读出数据,fd[1]则只能用于往管道写入数据,而不能反过来使用。如果要实现双向的数据传输,就应该使用两个管道。
默认情况下,这一对文件描述符都是阻塞的。如果用read系统调用来读取一个空的管道,则read将被阻塞,直到管道内有数据可读;用write系统调用往一个满的管道中写入数据,则write亦将被阻塞,直到管道内有足够多的空闲空间可用。但如果应用程序将fd[0]和fd[1]都设置为非阻塞的,则read和write会有不同的行为。
如果管道的写端文件描述符fd[1]的引用计数减少至0,即没有任何进程需要往管道中写入数据,则针对该管道的读端文件描述符fd[0]的read操作将返回0,即读到了文件结束标记(End Of File,EOF);反之,如果管道的读端文件描述符fd[0]的引用计数减少至0,即没有任何进程需要从管道读取数据,则针对该管道的写端文件描述符fd[1]的write操作将失败,并引发SIGPIPE信号。
管道内部传输的数据是字节流,且拥有一个容量限制,它规定如果应用程序不将数据从管道读走的话,该管道最多能被写入多少字节的数据。(自Linux内核 2.6.11起,管道容量的大小默认是65536字节)。我们可以使用fcntl函数来修改管道容量。
此外,socket的基础API中有一个socketpair函数。它能够方便地创建双向管道,其定义如下:
1 |
|
前三个参数的含义与socket系统调用的三个参数完全相同,但domain只能使用UNIX本地域协议族AF_UNIX,因为我们仅能在本地使用这个双向管道。
最后一个参数则和pipe系统调用的参数一样,只不过socketpair创建的这对文件描述符都是既可读又可写的。socketpair成功时返回0,失败时返回-1并设置errno。
dup函数和dup2函数
有时我们希望把标准输入重定向到一个文件,或者把标准输出重定向到一个网络连接(比如CGI编程)。这可以通过下面的用于复制文件描述符的dup或dup2函数来实现:
1 |
|
dup函数创建一个新的文件描述符,新文件描述符和原有文件描述符file_descriptor指向相同的文件、管道或者网络连接。并且dup返回的文件描述符总是取系统当前可用的最小整数值。
dup2和dup类似,不过它将返回第一个不小于file_descriptor_two的整数值。dup和dup2系统调用失败时返回-1并设置errno。
注意:通过dup和dup2创建的文件描述符并不继承原文件描述符的属性,比如close-on-exec和non-blocking等。
下面用dup函数实现了一个基本的CGI服务器:
1 |
|
使用之前的网络进行测试,服务器(192.168.141.137)先编译运行此代码,等待客户端进行连接;客户端(192.168.141.139)使用nc命令连接服务端对应端口。操作步骤如下:
1 | # 服务端 |
得到结果:

可以看到,服务器已经将标准输出内容重定向到网络连接,而在客户端的命令行中显示出来了。
过程中,我们先关闭标准输出文件描述符STDOUT_FILENO(其值是1),然后复制socket文件描述符connfd。因为dup总是返回系统中最小的可用文件描述符,所以它的返回值实际上是1,即之前关闭的标准输出文件描述符的值。这样一来,服务器输出到标准输出的内容(“abcd\n”)就会直接发送到与客户端连接对应的socket上,因此printf调用的输出将被客户端获得(而不是显示在服务器程序的终端上)。这就是CGI服务器的基本工作原理。
readv函数和writev函数
readv函数将数据从文件描述符读到分散的内存块中,即分散读;writev函数则将多块分散的内存数据一并写入文件描述符中,即集中写。(与bio的io形式很相似)。它们的定义如下:
1 |
|
fd参数是被操作的目标文件描述符。
vector参数的类型是iovec结构数组,用来描述一块内存区。其定义如下(之前也写过,再写一遍):
1 | struct iovec |
count参数是vector数组的长度,即有多少块内存数据需要从fd读出或者写入。
readv和writev在成功时返回读出/写入fd的字节数,失败则返回-1并设置errno。
考虑对于Web服务器,当Web服务器解析完一个HTTP请求之后,如果目标文档存在并且客户具有读取文档的权限,那么它就需要发送一个HTTP应答来传输文档。HTTP应答包含一个状态行、多个头部字段、1个空行和文档内容。其中前3部分内容可能被Web服务器放在一块内存中,而文档内容则通常被读入到另一块单独的内存中(通过read函数或者mmap函数)。我们并不需要把这两部分内容拼接在一起再发送,而是可以使用writev函数将它们同时写出。
我们可以通过下面的程序来体验writev的功能:
1 |
|
使用之前的网络进行测试,服务器(192.168.141.137)在代码的同一个文件夹中创建一个testfile.txt文件,写一些话(注意使user有权限,可以chmod修改权限),然后编译运行该代码。客户端通过nc命令向服务器发起连接。具体过程如下:
1 | # 服务器 |
在客户端得到服务器上的文件内容:

可以看出,得到了期望的结果。
sendfile函数
sendfile函数在两个文件描述符之间直接传递数据(完全在内核中操作),从而避免了内核缓冲区和用户缓冲区之间的数据拷贝,效率很高,这被称为零拷贝。其定义如下:
1 |
|
in_fd参数是待读出内容的文件描述符,out_fd参数是待写入内容的文件描述符。
offset参数指定从读入文件流的哪个位置开始读,如果为空,则默认是读入文件流的起始位置。
count参数指定在文件描述符in_fd和out_fd之间传输的字节数。
sendfile调用成功返回传输的字节数,失败则返回-1并设置errno。
注意:该函数的man手册指出,
in_fd必须是一个支持类似mmap函数的文件描述符,即它必须指向真实的文件,不能是socket和管道;而out_fd则必须是一个socket。由此可见,sendfile几乎是专门为网络上传输文件而设计的。
下面我们使用sendfile函数将服务器(192.168.141.137)上的一个文件传送给客户端(192.168.141.139)。
1 |
|
服务器在代码目录下建立一个文件demofile.txt,写一些内容,然后编译运行上面代码,等待客户端连接。具体操作流程如下:
1 | # 服务器 |
然后就可以在客户端的命令行中得到预期的结果,即客户端获取到了服务器上目标文件的内容:

sendfile相比readv和writev函数,并没有为目标文件分配任何用户空间的缓存,也没有执行读取文件的操作,但同样实现了文件的发送,其效率显然更高。
mmap函数和munmap函数
mmap函数用于申请一段内存空间。可以将这段内存作为进程间通信的共享内存,也可以将文件直接映射到其中。munmap函数则释放由mmap创建的这段内存空间。它们的定义如下:
1 |
|
start参数允许用户使用某个特定的地址作为这段内存的起始地址,如果它被设置成NULL,则系统自动分配一个地址。
length参数指定内存段的长度。
prot参数用来设置内存段的访问权限,它可以取以下几个值的按位或:
- PROT_READ,内存段可读
- PROT_WRITE,内存段可写
- PROT_EXEC,内存段可执行
- PROT_NONE,内存段不能被访问
flags参数控制内存段内容被修改后程序的行为,它可以被设置为下表中某些值的按位或(仅列出了常用的值,其中MAP_SHARED和MAP_PRIVATE是互斥的,不能同时指定)。
| 常用值 | 含义 |
|---|---|
| MAP_SHARED | 在进程间共享这段内存。对该内存段的修改将反映到被映射的文件中。它提供了进程间共享内存的POSIX方法。 |
| MAP_PRIVATE | 内存段为调用进程所私有。对该内存段的修改不会反映到被映射的文件中。 |
| MAP_ANONYMOUS | 这段内存不是从文件映射而来的。其内容被初始化为全0。这种情况下,mmap函数的最后两个参数将被忽略。 |
| MAP_FIXED | 内存段必须位于start参数指定的地址处。start必须是内存页面大小(4096字节)的整数倍。 |
| MAP_HUGETLB | 按照“大内存页面”来分配内存空间。“大内存页面”的大小可通过/proc/meminfo文件来查看。 |
fd参数是被映射文件对应的文件描述符。它一般通过open系统调用获得。
offset参数设置从文件的何处开始映射(对于不需要读入整个文件的情况)。
mmap函数成功时返回指向目标内存区域的指针,失败则返回MAP_FAILED((void*)-1)并设置errno。
munmap函数成功时返回0,失败则返回-1并设置errno。
我们将在后面进一步利用mmap函数来实现进程间共享内存。
splice函数
splice函数用于在两个文件描述符之间移动数据,也是零拷贝操作。其定义如下:
1 |
|
fd_in参数是待输入数据的文件描述符。如果fd_in是一个管道文件描述符,则off_in参数必须设置为NULL,若不是管道文件描述符,则表示输入数据流从何处开始读取数据(此时若将off_in设置为NULL,则表示从输入流的当前偏移位置读入)。
fd_out/off_out参数的含义与fd_in/off_in相似,不过用于输出数据流。
len参数指定移动数据的长度;而flags参数控制数据如何移动,可以被设置成下表某些值的按位或。
| 常用值 | 含义 |
|---|---|
| SPLICE_F_MOVE | 如果合适的话,按整页内存移动数据。这只是给内核一个提示。不过,它的实现存在bug,自内核2.6.21后,实际上没有效果。 |
| SPLICE_F_NONBLOCK | 非阻塞的splice操作,但实际效果还会受文件描述符本身的阻塞状态影响。 |
| SPLICE_F_MORE | 给内核一个提示:后续的splice调用将读取更多数据 |
| SPLICE_F_GIFT | 对splice没有效果 |
使用splice函数时,fd_in和fd_out必须至少有一个是管道文件描述符。splice函数调用成功时返回移动字节的数量(可能是0,表示没有数据需要移动,发送在从管道中读取数据,而没有被写入任何数据时)。调用失败时返回-1并设置errno。常见的errno见下表:
| 错误 | 含义 |
|---|---|
| EBADF | 参数所指文件描述符有错 |
| EINVAL | 目标文件系统不支持splice,或者目标文件以追加方式打开,或者两个文件描述符都不是管道文件描述符,或者某个offset参数被用于不支持随机访问的设备(如字符设备) |
| ENOMEM | 内存不够 |
| ESPIPE | 参数fd_in(或fd_out)是管道,但off_in(或off_out)不为NULL |
下面使用splice函数来实现一个零拷贝的回射服务器,它将客户端发送的数据原样返回到客户端,具体代码如下:
1 |
|
服务器(192.168.141.137)编译运行代码,等待客户端连接并发送数据,客户端的命令行中将回显自己发送的数据。运行结果如下:

在过程中,通过splice函数将客户端的内容读入到pipefd[1]中,然后再使用splice函数从pipefd[0]中读出该内容到客户端,从而实现了简单高效的回射服务。整个过程未执行recv/send操作,也未涉及用户空间和内核空间之间的数据拷贝。
tee函数
tee函数在两个管道文件描述符之间复制数据,也是零拷贝操作。它不消耗数据(splice的移动操作会消耗数据),因此,源文件描述符上的数据仍然可以用于后续的读操作。其定义如下:
1 |
|
该函数参数的含义与splice相同(但fd_in和fd_out必须都是管道文件描述符)。tee调用成功返回在两个文件描述符之间复制的字节数(返回0表示没有复制任何数据),失败则返回-1并设置errno。
下面使用tee函数与splice函数,实现linux中的tee程序(将标准输入同时输出到终端和文件的程序)。
1 |
|
在管道间复制数据,并不会消耗管道的数据。
fcntl函数
fcntl函数提供了对文件描述符的各种控制操作。另一个常见的控制文件描述符属性和行为的系统调用是ioctl,而且ioctl比fcntl能够执行更多的控制。但是,对于控制文件描述符常用的属性和行为,fcntl函数是由POSIX规范指定的首选方法。其定义如下:
1 |
|
fd参数是被操作的文件描述符。
cmd参数指定执行何种类型的操作。根据操作类型的不同,该函数可能还需要第三个可选参数arg。
fcntl支持的常用操作及其参数如下表所示:

fcntl调用成功时返回值如上表最后一列所示,失败则返回-1并设置errno。
在网络编程中,fcntl函数通常用来将一个文件描述符设置为非阻塞的,可以这样实现:
1 | int setnonblocking(int fd) |
Linux服务器程序规范
期待后续更新。。 ——0917
更新来了! ——0923
服务器程序规范,指除了网络通信外,服务器程序通常还必须考虑的一些模板式的细节问题,包括:
- Linux服务器程序一般以后台进程(守护进程—daemon)形式运行。守护进程的父进程通常是
init进程(PID为1的进程)。 - Linux服务器程序通常有一套日志系统(在/var/log目录下),至少能输出日志到文件。
- 服务器程序一般以某个专门的非root身份运行。比如mysqld、httpd等后台进程,分别拥有自己的运行账户mysql、apache。
- 服务器程序通常是可配置的,需要处理很多命令行选项,若一次运行的选项太多就可以用配置文件来管理(存放在/etc目录下)。
- Linux服务器进程通常会在启动的时候生成一个PID文件并存入/var/run目录中,以记录该后台进程的PID。
- 服务器程序通常需要考虑系统资源和限制,以预测自身能承受多大负荷,比如进程可用文件描述符总数和内存总量等。
下面来探讨一些主要的规范。
日志
Linux系统日志
Linux提供一个守护进程来处理系统日志——syslogd,不过现在Linux系统上使用的都是它的升级版——rsyslogd。rsyslogd守护进程既能接收用户进程输出的日志,又能接收内核日志。下面是Linux的系统日志体系:

用户进程通过调用syslog函数生成系统日志,该函数将日志输出到一个UNIX本地域socket类型的文件/dev/log中,rsyslogd则监听该文件以获取用户进程的输出。
内核日志用printk等函数打印至内核的环状缓存(ring buffer)中。环状缓存的内容直接映射到/proc/kmsg文件中,rsyslogd通过读取该文件获得内核日志。
syslog函数
应用程序使用syslog函数与rsyslogd守护进程通信,函数定义如下:
1 |
|
该函数采用可变参数来结构化输出。
priority参数是所谓的设施值与日志级别的按位或。设施值的默认值为LOG_USER,之后的讨论也只限于这一种设施值。日志级别有如下几个:
1 |
下面的函数可以改变syslog的默认输出方式,进一个结构化日志内容:
1 |
|
ident参数指定的字符串将被添加到日志消息的日期和时间之后,它通常被设置为程序的名字。
logopt参数对后续syslog调用的行为进行配置,它可以去下列值的按位或:
1 |
facility参数可用来修改syslog函数中的默认设施值。
此外,日志的过滤也很重要。程序开发阶段可能需要输出很多调试信息,而发布之后我们有需要将这些调试信息关闭。解决这个问题的方法并不是在程序发布前删除代码,而是简单地设置日志掩码。使日志级别大于日志掩码的日志信息被系统忽略:
1 |
|
maskpri参数指定日志掩码值。该函数始终成功,并返回调用进程先前的日志掩码值。
最后,可使用如下函数关闭日志功能:
1 |
|
声明(2021.9.23)
这篇博客至此,已经3w多字了,每天的阅读进度只有2页左右,却花费了很多的时间。这些时间大多花在博客上,本来的想法是把书中重点,以及自己的心得记录一下,却不知不觉地成了几乎是文章的复制,效率很低,尤其现在事情多了起来,完完全全把书抄一遍在博客上显然是不可取的。这本书说实话,大篇幅都是函数指南,而系统底层本质说的很少,所以在这本书上耗费过多的时间不值得。于是,接下来的记录会尽量精简。
用户信息
UID、EUID、GID和EGID
解释:UID(真实用户ID),EUID(有效用户ID),GID(真实组ID),EGID(有效组ID)
在#include<sys/types.h>和#include<unistd.h>头文件下有一组set/get方法以设置/获取这些信息。
一个进程拥有两个用户ID:UID和EUID。EUID存在的目的是方便资源访问:它使得运行程序的用户拥有该程序的有效用户的权限。例如,普通用户访问su程序,实际上其有效用户ID为root的ID。
文件可以设置set-user-id标志,这样的话,任何普通用户运行该程序时,其有效用户都是文件的所有者。
下面可以测试UID和EUID的区别:
1 |
|
编译该文件,得到可执行文件(名为test_uid),将其所有者设置为root,并设置该文件的set-user-id标志,然后运行程序查看UID和EUID。具体操作如下:
1 | $ sudo chown root: root test_uid # 修改目标文件的所有者为root |
从输出来看,该进程的UID是启动程序的用户ID,而EUID则是root用户(文件所有者)的ID。
进程间关系
进程组
Linux下每个进程都隶属于一个进程组,每个进程组都有一个首领进程,其PID与PGID相等,我们可以获取/设置指定进程的进程组ID(PGID)。
1 |
|
getgpid获得当前进程的进程组ID,失败返回-1并设置errno。
setgpid为进程号为pid的进程(pid为0,表示当前进程)设置进程组ID。成功返回0,失败返回-1并设置errno。
一个进程只能设置自己或者子进程的PGID。并且,当子进程调用exec系列函数后,我们也不能再在父进程中对它设置PGID。
会话
一些有关联的进程组将形成一个会话(session),我们可以创建/获取会话:
1 |
|
setsid不能由进程组的首领进程调用,否则将产生错误。对于非组首领的进程,该函数创建会话,并有如下额外效果:
- 调用进程称为会话的首领,也是新会话的唯一成员
- 新建一个进程组,其PGID就是调用进程的PID,调用进程称为该组的首领
- 调用进程将甩开终端(如果存在)
setsid调用成功返回新进程组的PGID,失败则返回-1并设置errno。
getsid调用成功返回当前进程所处的会话ID,失败则返回-1并设置errno。
ps命令
使用ps命令可以查看进程、进程组和会话之间的关系。
1 | $ ps -o pid,ppid,pgid,sid,comm | less |
可以看出,ps和less命令的父进程是bash命令(PPID),3条命令创建了一个会话(SID: 1943)和两个进程组(PGID分别为1943和2298)。bash是会话的首领,ps命令是进程组2298的首领。
系统资源限制
Linux上运行的程序都会受到资源限制的影响,比如物理设备限制(CPU数量、内存数量等)、系统策略限制(CPU时间等)、以及具体实现的限制(文件名最大长度等)。可以通过如下一对函数来读取和设置:
1 |
|
rlim参数是rlimit结构体类型的指针,其结构体定义如下:
1 | struct rlimit |
rlim_t是一个整数类型,它描述资源级别。rlim_cur指定资源的软限制(最好不要超过),rlim_max指定资源的硬限制(软限制的上限)。
setrlimit和getrlimit成功时返回0,失败则返回-1并设置errno。
改变工作目录和根目录
有些服务器程序需要改变工作目录和根目录。如Web服务器的逻辑根目录并非文件系统的根目录“/”,而是站点的根目录(一般是/var/www/),可以获取进程当前工作目录和改变进程工作目录:
1 |
|
getcwd成功时返回一个指向目标存储区(buf指向的存储区或是getcwd在内部动态创建的缓存区)的指针,失败则返回NULL并设置errno。若内部动态创建,则需要手动释放内存。
还可以改变进程的根目录:
1 |
|
path参数指定要切换到的目标根目录。它成功时返回0,失败则返回-1并设置errno。
chroot并不改变进程的当前工作目录,所以调用chroot后,仍然需要使用chdir("/")来将工作目录切换到新的根目录。
服务器程序后台化
如何在代码中让一个进程以守护进程的方式运行?守护进程的编写遵循一定的步骤,下面通过一个具体实现来探讨:
1 | bool daemonize() |
实际上,Linux提供了完成同样功能的库函数:
1 |
|
nochdir指定是否改变工作目录,若传递0,则工作目录被设置为“/”,否则继续使用当前工作目录。
noclose参数为0时,标准输入、标准输出和标准错误输出都被重定向到/dev/null文件中,否则依然使用原来的设备。
该函数成功时返回0,失败时返回-1并设置errno。
高性能服务器程序框架
暂略,目前看不懂 ——9.24
Ex:问题记录
自己的Ubuntu虚拟机连不上网?
先用ifconfig查看网卡接口是启动,而ifconfig -a 可以查看所有的网卡接口。若ifconfig没有出现对应的网卡接口,可以执行
dhclient <网卡名称>来动态获取IP地址,以恢复网络连接。
