主要来源:马士兵课程《深入io到epoll与linux内核的系统调用》
预备
学习方法:学一个技术,找到问题,推理解决

计算机的组成有内存(主存),cpu,io设备等。程序运行在内存中,内存可以理解成一个线性地址空间,内存里放的是运行时的程序,程序有各种指令和数据。
内存可以分为两个部分:内核空间 和 用户空间
其中有一些概念:
保护模式:参考https://zhuanlan.zhihu.com/p/42309472
用户空间,内核空间:OS的进程空间可以分为用户空间和内核空间,它们有不同的执行权限。
用户态,内核态
切换:用户态到内核态切换的三种方式(系统调用-软中断,异常-如缺页中断,外设中断)。态的切换具有比较大的开销。
计算机刚启动时,首先会将内核程序加载进内存。内核是一种特殊的软件程序,能够控制计算机的硬件资源(比如:协调CPU资源,分配内存资源,提供稳定的环境供应用运行)。
保护模式中存在一个table(全局描述符表,GDT),来进行约束,描述哪部分是内核空间,哪部分是用户空间。GDT的地址会放到cpu的寄存器中。比如,tomcat中有条指令需要取的数据地址在内核空间,那么就会报错,这样来保护内核不受到不明程序的破坏。
为什么要有内核程序呢?
假如有一块硬盘,所有想访问它的用户程序都需要编写其驱动,并且开发很多东西。而利用内核程序来管理所有硬件设备,向外提供接口给应用程序访问,这样符合工程学的理论。内核提供对硬件设备的管理和调控,同时保护了系统的安全。
通常编写用户程序时,需要导入一些库,这些库称为api(应用程序编程接口)。但也不是说库就可以直接访问内核空间,而是库调用内核暴露的方法(系统调用)。
应用程序–>库/shell–>系统调用–>内核
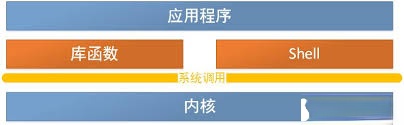
系统调用(system call)
是指运行在用户空间的程序向操作系统内核请求需要更高权限运行的服务。系统调用提供用户程序与操作系统之间的接口。大多数交互式操作需求在内核态运行。如设备IO操作或进程间通信。
系统调用将Linux整个体系分为用户态和内核态。
这时候来思考:内核是程序,shell是程序,tomcat也是程序,如果cpu只有1核,那么某一个程序在执行时,是不是说这个程序在cpu上永久执行下去,其他程序就无法进入cpu了吗?
【因为在开发时,自己并没有写相关程序执行多少毫秒就切换给其他程序的语句,程序并没有让出过】
这里面有很多东西:cpu中有一个晶振的概念,产生有规律的震动,每次震动产生一个事件。这之中有一套系统称为中断。这是非常重要的概念,因为没有中断的话,一个程序就会死在cpu上。
中断是一个宏观名词,分为硬中断和软中断。
- 硬中断(hardirq)。硬中断是由与系统相连的外设(比如网卡,硬盘,时钟)产生的。主要用来通知操作系统外设状态的变化。比如网卡收到数据包的时候,就会发出一个中断。
- 软中断(softirq)。为了满足实时系统的需求,中断处理应该越快越好。linux为了实现这个特点,当中断发生时,硬中断处理哪些短时间就可以完成的工作,而将哪些处理时间比较长的工作,放在中断之后来完成,也就是软中断来完成。比如陷阱陷入(80中断),此时cpu开始切换态。
软中断非常像硬中断,然而它们仅仅是由当前正在运行的进程所产生的。通常软中断用于处理I/O请求,软中断仅与内核想联系,并且不会直接地中断cpu。
软中断是一种需要内核为正在运行的进程去做一些事情(I/O,系统调用等)的请求。
I/O
什么是I/O?
I/O(Input/Output),即输入输出,通常指数据在存储器或其他周边设备之间的输入和输出,是信息处理系统(如计算机)与外部世界(人类或另一信息处理系统)之间的通信。
I/O的工作模式(消息通信机制):
同步:调用者会主动等待调用结果。按照“调用者”线程在等待调用结果时的状态可以分为:
- 阻塞:线程被操作系统挂起
- 非阻塞:线程不被操作系统挂起,可以处理其他事情
异步:调用者发起一个异步调用,然后立即返回去做别的事。“被调用者”通过状态、通知、回调函数等手段来通知“调用者”。
异步IO不是FIFO有序的,例如进程A与进程B先后对一个端口发起了异步读操作,有可能事进程B先得到读操作的结果。
同步/异步,阻塞/非阻塞还需要仔细甄别!
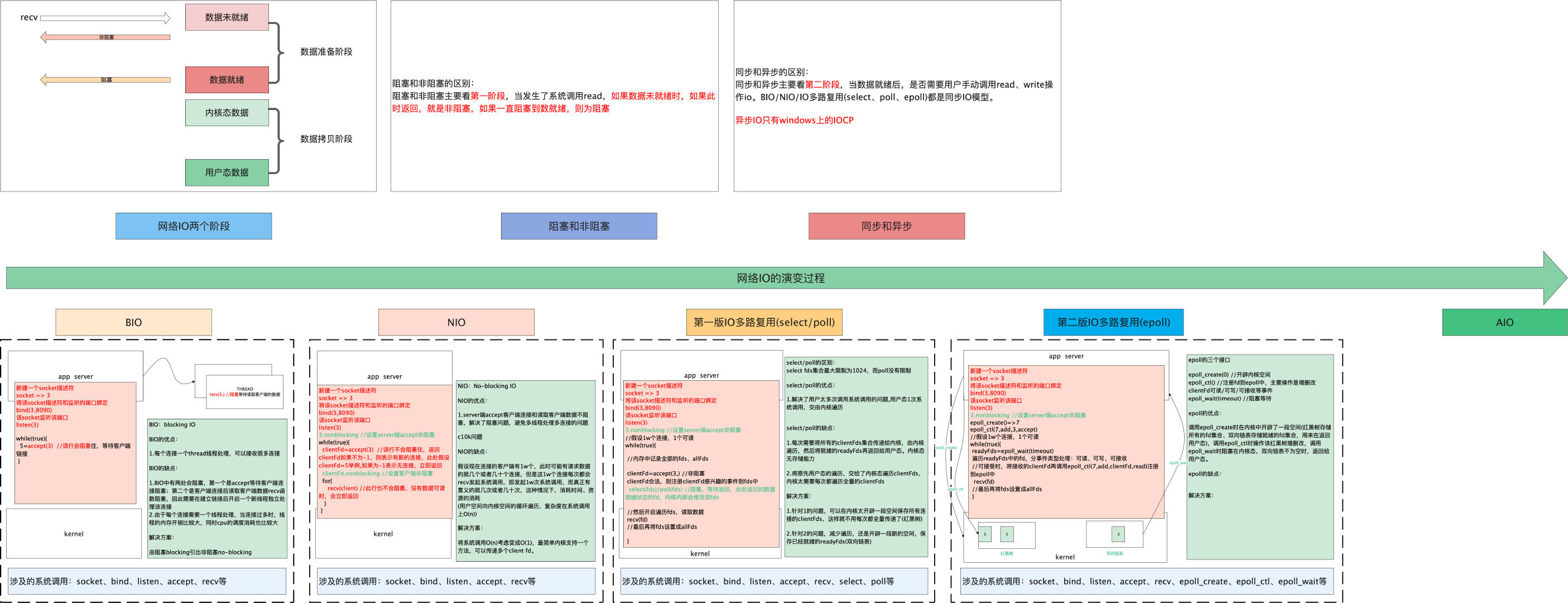
我们讨论网络I/O一般针对linux操作系统而言,网络I/O的发展过程是随着linux内核的演变而变化的,因此网络I/O可以大致分为以下的几个阶段。每个阶段,都是对于之前阶段的缺陷进行的改进。下面就对每个阶段网络I/O解决了哪些问题、优点、缺点进行剖析:

同步阻塞模型(BIO)
BIO(Blocking-IO)指的是,数据的读取写入阻塞在这个线程内等待完成(处理过程中线程被阻塞)。
使用经典的烧开水例子来解释:这里假设一个烧开水的场景,有一排水壶在烧开水,BIO的工作模式就是, 叫一个线程停留在一个水壶那,直到这个水壶烧开,才去处理下一个水壶。但是实际上线程在等待水壶烧开的时间段什么都没有做。
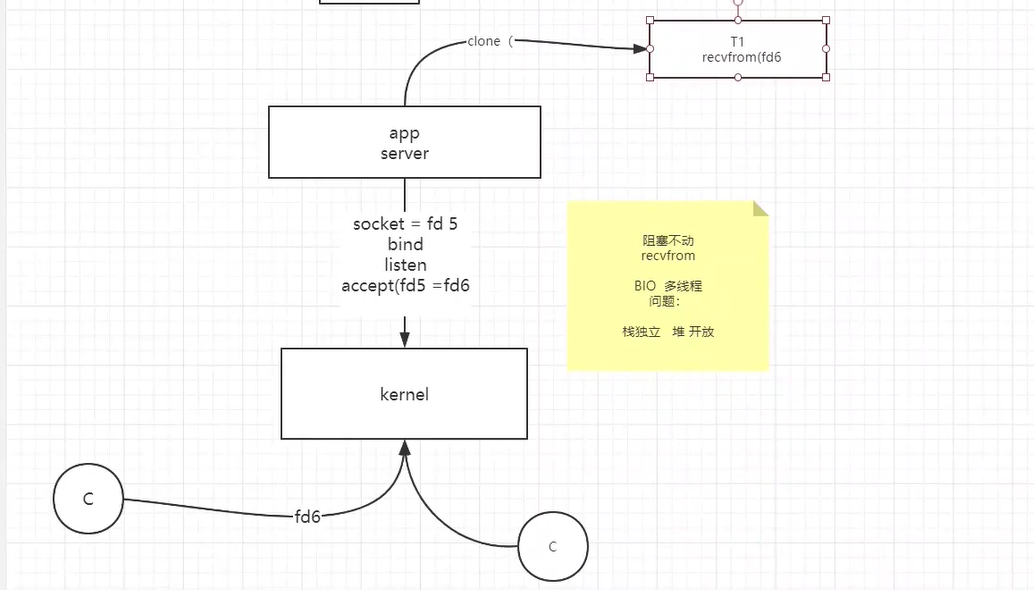
BIO可以利用多线程模型来优化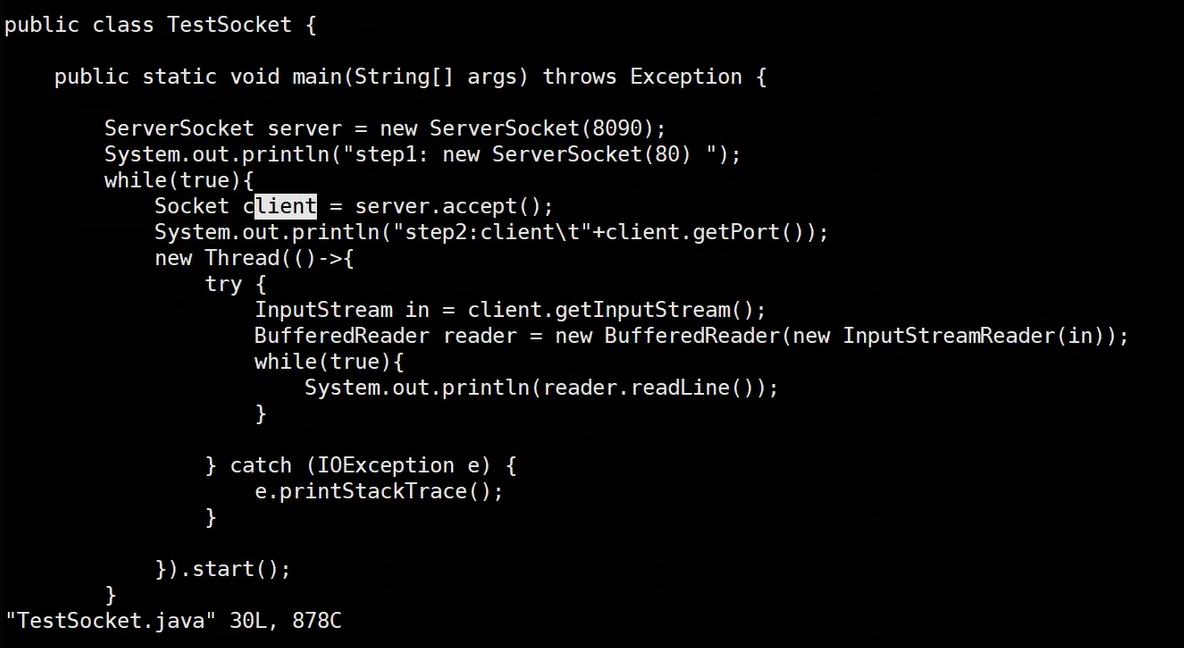
但是多线程模型也有很明显的问题:
- 需要
clone线程,造成了开销 - 线程越多,cpu依次询问每个线程,但是晶振时间一过又去访问别的程序,来回切换其实需要等很久才能真正去处理数据。
问题的表面是多线程,但是实际上其根源问题是因为堵塞。一个client对进程造成了堵塞,所以才会将这个client的数据传输交给一个线程来防止进程的堵塞。
同步非阻塞模型(NIO)
NIO(Non-Blocking IO 或 new IO),说的是单线程可以以非阻塞的方式处理多个I/O。
NIO有两层含义:
- (程序框架)new io 新的io框架
- (内核调用)SOCK_NONBLOCK 非阻塞
将每个socket fd设置为非阻塞,等待的时候会立刻返回,如果没有数据就会显示错误码。将所有client轮询以检查是否有数据进行传输。这样单线程就能够处理多个client。
依旧用烧水壶的例子来说的话,NIO的做法是让一个线程不断的轮询每个水壶的状态,看看是否有水壶的状态发生了改变,从而进行下一步的操作。
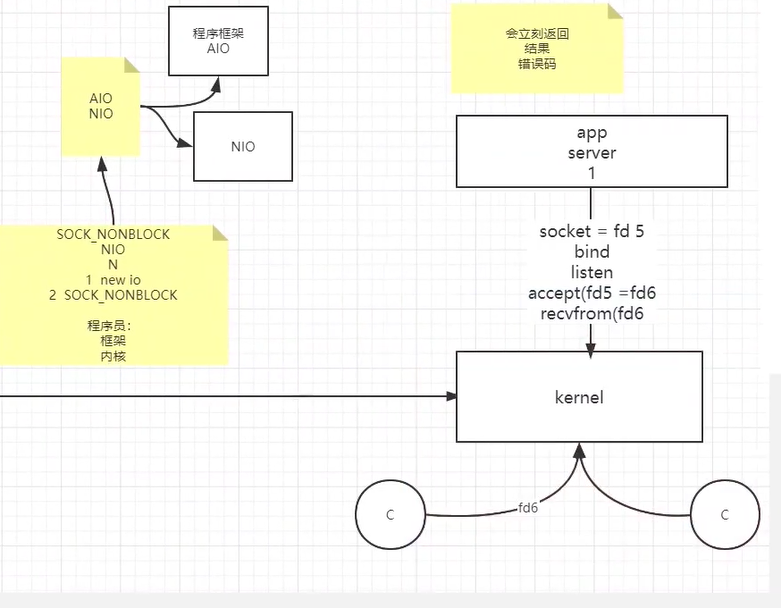
单线程同步非阻塞的问题:
- 轮询可能造成很大的时间浪费。比如每轮询一次,有1000个client,但每次只有1个有数据,那么将会有999次系统调用被浪费。
有很多系统调用被浪费了,那么如何解决呢? –> 多路复用
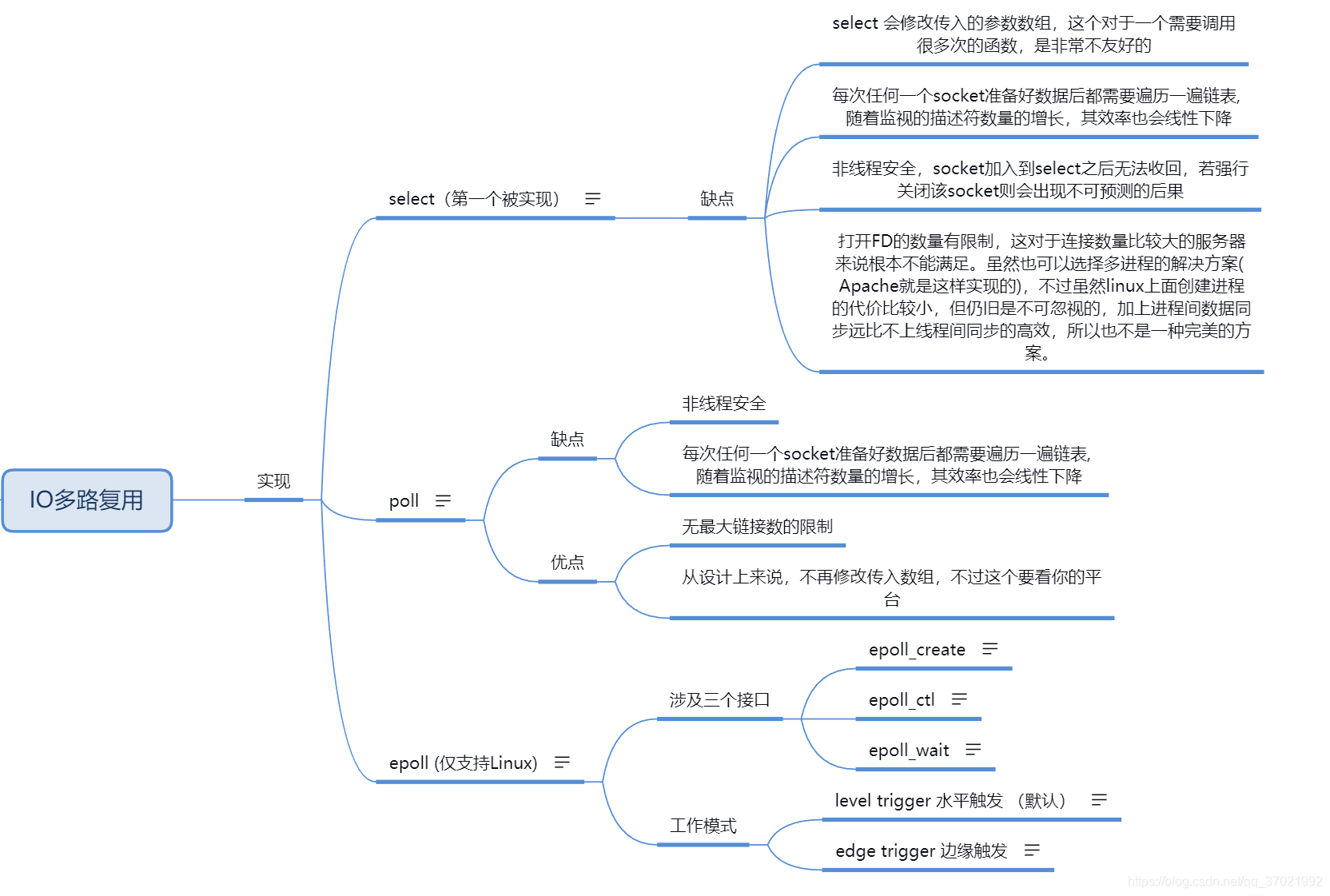
多路复用(select/polll)
每次循环client就变成了 O(1) select(fd1000s), O(3): accept read recvfrom。减少了系统调用。返回的是事件,表示哪些fd可以用,但是是自己去用,是同步的。 select是内核内部自己遍历所有fd。相比NIO进行所有fd次数的态的切换开销更小,但还是有浪费。
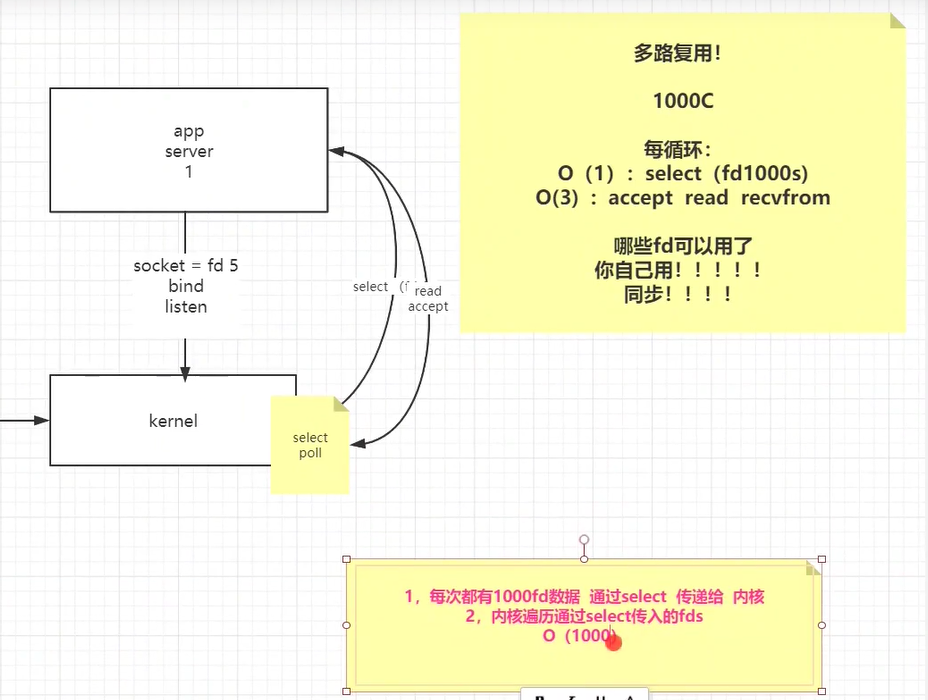
select的api:
1 | // readfds:关心读的fd集合;writefds:关心写的fd集合;excepttfds:异常的fd集合 |
select 目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。select 的一 个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在 Linux 上一般为 1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但 是这样也会造成效率的降低。
poll的api:
1 | int poll (struct pollfd *fds, unsigned int nfds, int timeout); |
pollfd 结构包含了要监视的 event 和发生的 event,不再使用 select“参数-值”传递的方式。同时,pollfd 并没有最大数量限制(但是数量过大后性能也是会下降)。 和 select 函数一样,poll 返回后,需要轮询 pollfd 来获取就绪的描述符。
select的问题:
- 每次都有很多fd数据通过select传递给内核
- 内核遍历传入的fds,同样具有比较大的复杂度
多路复用(epoll)
epoll_create()在内核开辟一个空间(efd8),服务端调用epoll_ctr()将需要关注的socket文件描述符以及想要关注的事件添加到开辟的空间。此时程序会调用epoll_wait(),询问epoll fd8。假设客户端到来,经过TCP三次握手,此事件到来时 开辟另一个空间,将fd5放入。
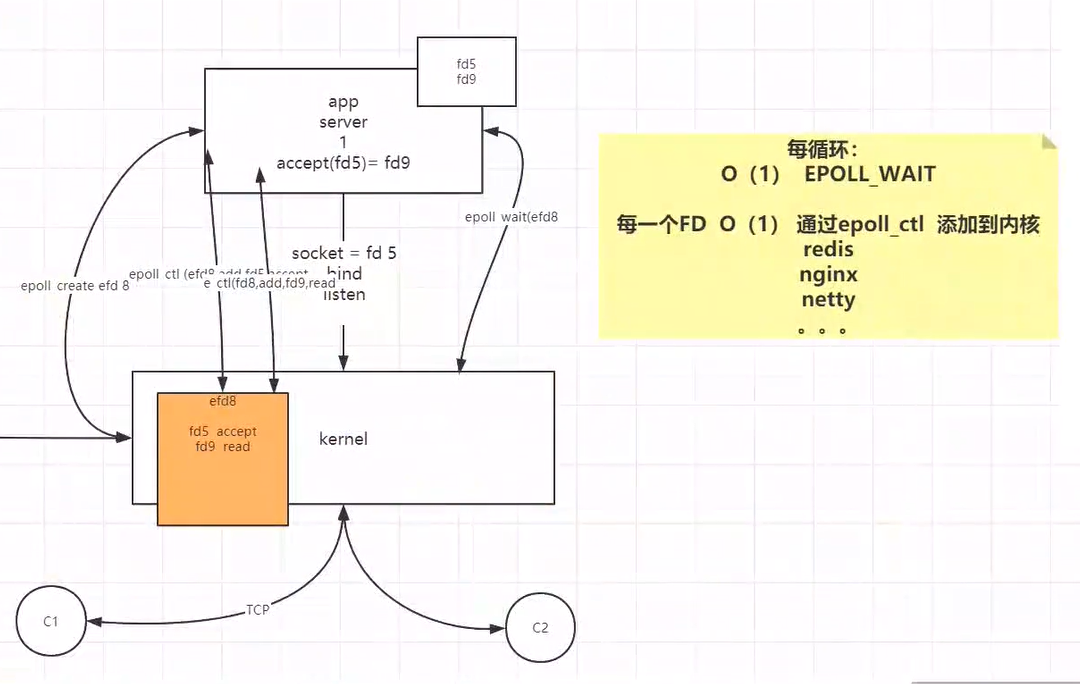
epoll提供的api:
1 | //创建epollFd,底层是在内核态分配一段区域,底层数据结构红黑树+双向链表 |
epoll的工作模式:
- LT(level triggered)模式,是缺省的工作方式,并且同时支持 block 和 no-block socket.在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的 fd 进行 IO 操作。如果你不作任何操作,内核还是会继续通知你的。
- ET(edge-triggered)模式,是高速工作方式,只支持 no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过 epoll 告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了(比如,你在发送,接收或者接收请求,或者发送接收的数据少于一定量时导致了一个 EWOULDBLOCK 错误)。但是请注意,如果一直不对这个 fd 做 IO 操作(从而导致它再次变成未就绪),内核不会发送更多的通知(only once)。
ET 模式在很大程度上减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。epoll 工作在 ET 模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
底层为epoll的应用:redis, nginx, netty, kafka
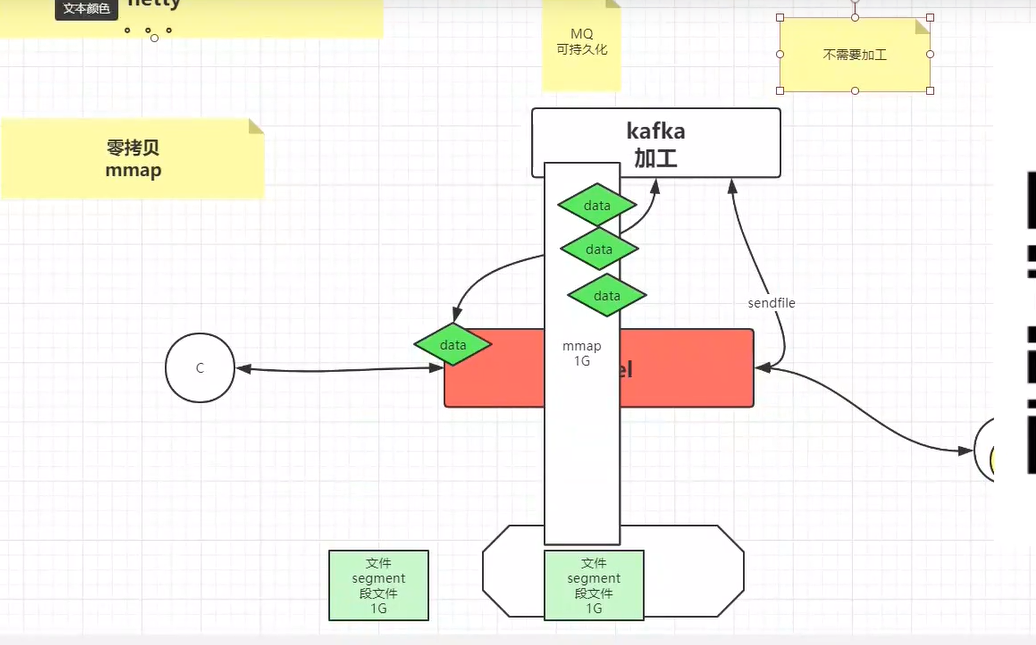
零拷贝(sendfile),mmap
mmap可以在程序外开辟一个存储空间,这个空间应用程序可以访问,内核也可以访问,是文件的一个映射。
下面是kafka模型的一个例子:
IO多路复用(select, poll, epoll)总结:
网络IO各个阶段的总结:
Linux底层追踪手段
授人以鱼不如授人以渔。上面对于epoll到系统调用的分析主要是通过以下linux命令进行操作的。
查看帮助文档
例如:
man 2 socket,其中的2表示系统调用nc(netcat)
类似于网络server和客户端,可以模拟tomcat
1
2
3
4
5// 在本地8080端口开启监听(服务端)
nc -l localhost 8080
// 客户端建立连接(会随机分配端口号),可以发送数据
nc localhost 8080linux中进程查询
1
ps -fe | grep <进程名>(如nc)
查询网络状态
1
netstat -natp
a表示all,所有;t表示tcp,p表示进程
查看进程
linux中一切皆文件,进程也是一个文件。
1
2
3
4
5cd /proc/<PID>(如1484)
// 查看文件描述符
cd fd
ll 或 ls -l其中
fd目录保存了该进程的文件描述符,task目录保存了该进程的线程。追踪一个程序有几个线程,并且每个线程对系统有哪些系统调用
1
strace -ff -o ./xxoo java TestSocket
-ff表示fork fork,连主线程子线程都追踪;-o表示追踪内容记录到文件中;./xxoo是文件的前缀;后面是执行程序。
可以用vim查看具体某个线程的内容,如
vi xxoo.1639vim中查询某个词 /<内容> , 设置行号 : set nu
追踪文件
1
tail -f xxoo.1638
其中-f表示阻塞,一直追踪
图表总结
下面两张图是本文的总结。该课程弄明白了IO框架的演变过程,但其中还有很多细节值得学习,后续也会在本文中进行不断的补充。

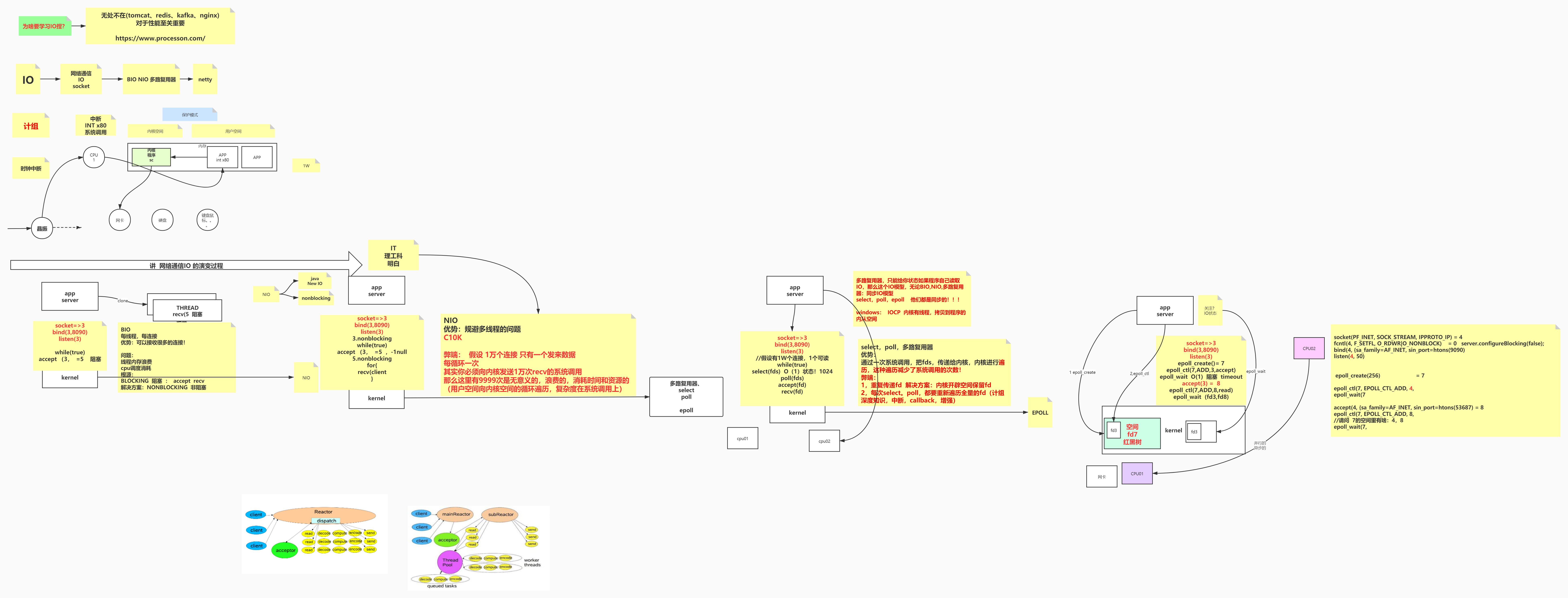
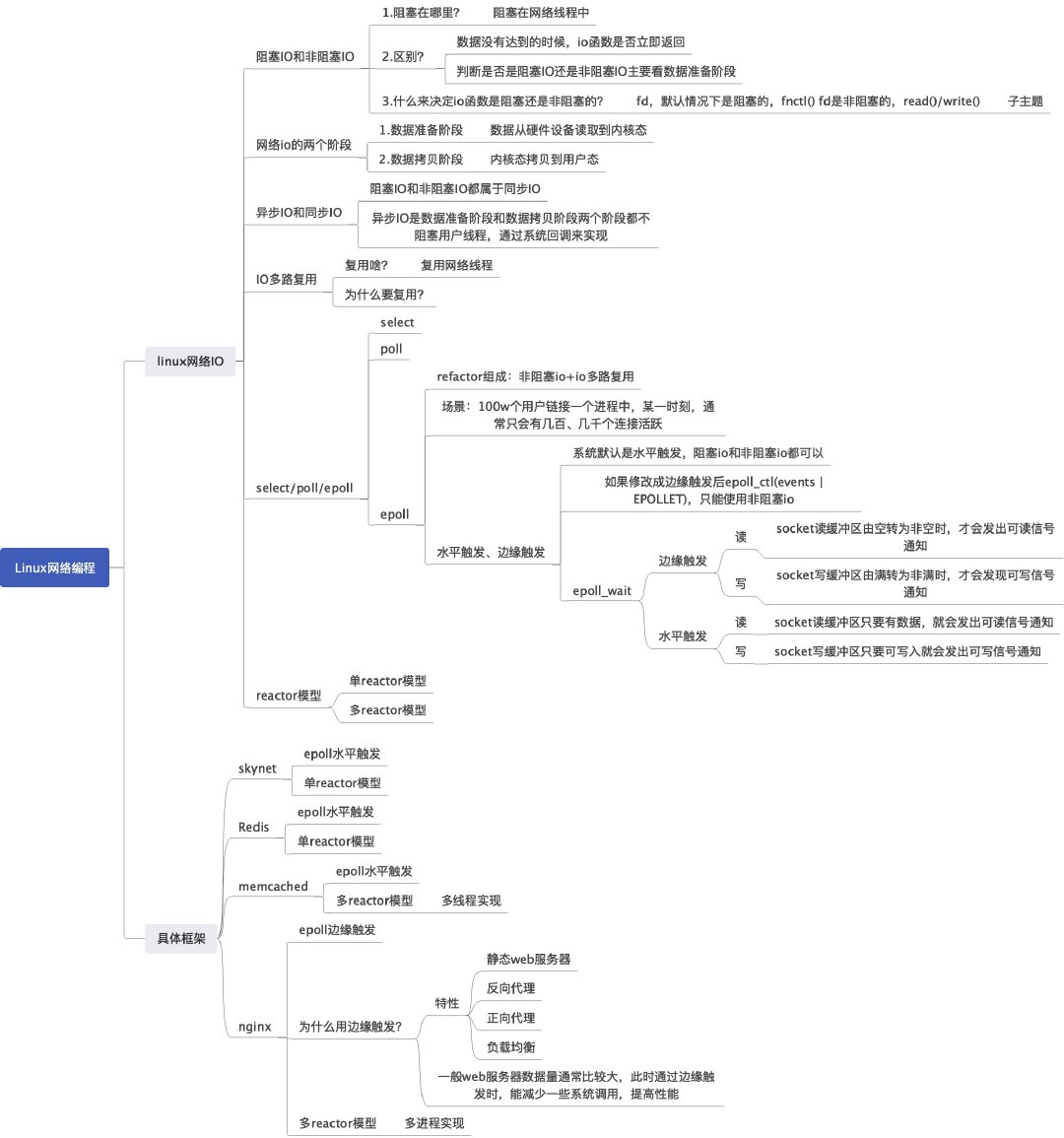
参考资料
- https://zh.wikipedia.org/wiki/I/O
- https://zhuanlan.zhihu.com/p/353692786
- https://blog.csdn.net/weixin_40413961/article/details/106485833
- https://blog.csdn.net/Crazy_Tengt/article/details/79225913
补充记录:
- 2021.4.12:补充了预备部分的内容,对名词做出解释,优化语句的流畅感。
- 2021.4.13:完善IO部分内容,添加相关说明以及多路复用模型相关api,添加参考资料
最近在为毕设发愁,暂时停更一会。