前言
最近想让提交的几个磁盘请求按确定的顺序执行,这亟需一种同步机制来提供这种实现。于是,调研并学习了linux下的一个轻量级线程同步机制——completion.
一般而言,在操作系统的多线程中,你没有办法预测OS是否将为你的线程选择一个正确的顺序。所以在操作共享变量时,需要谨慎,并在必要的时候使用某些机制来同步线程[1]。
该文章仅探讨线程同步机制,具体地,是linux中的completion线程同步机制。
completion
内核编程中常见的一种模式是,在当前线程之外初始化某个活动,然后等待该活动的结束。这个活动可能是:创建一个新的内核线程或者新的用户进程、对一个已有进程的某个请求,或者某种类型的硬件动作等[2]。在这种情况下,可以使用很多方式(如信号量)来同步这两个任务。同时,内核中提供了另一种轻量级线程同步机制——completion,它允许一个线程通知另一个线程某个工作已经完成。
具体地,在我的需求中,要求一个线程通过系统调用对硬件设备进行读写访问,并确保一系列读写访问的顺序以及共享变量的正确更新。流程如下:
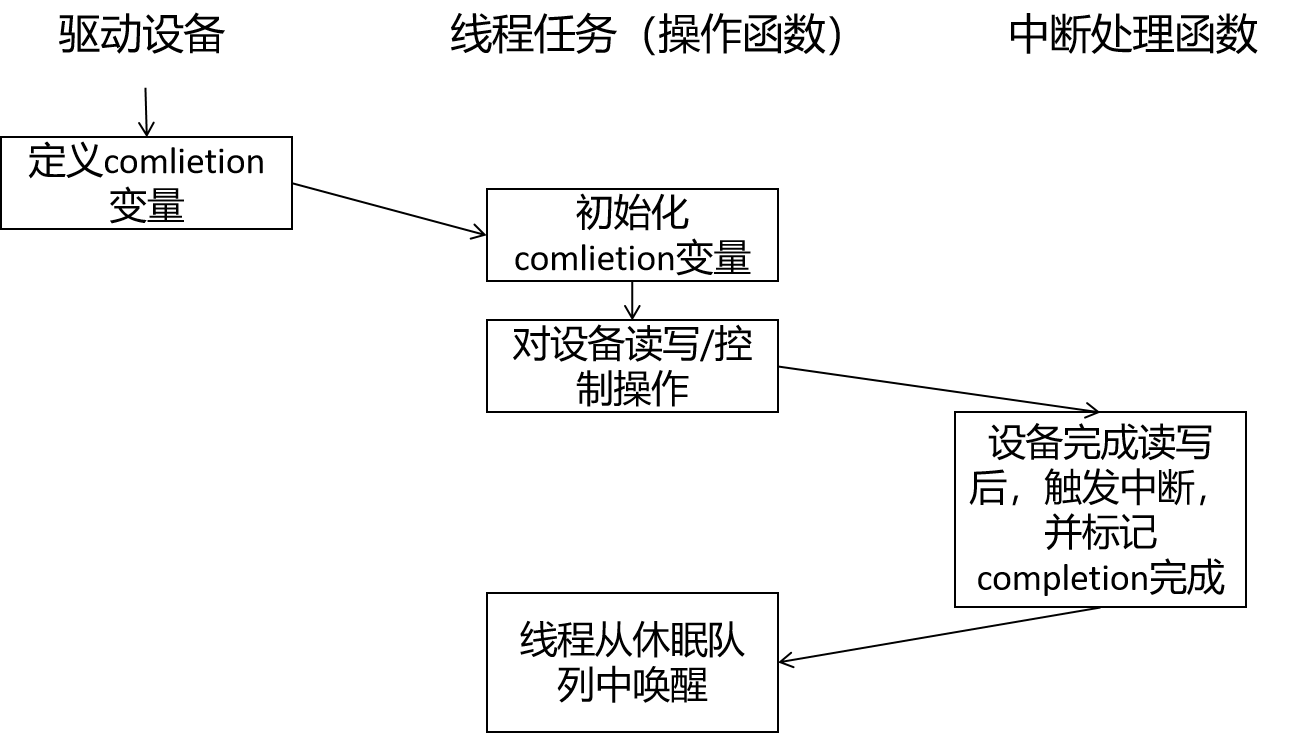
线程任务在调用系统调用对设备读写/控制后,就等待completion的完成,线程进入休眠队列中。
completion的操作并不算复杂,在使用之前初始化、完成操作后标记completion完成以及在需要线程等待的地方调用等待completion的函数。
接下来就具体来了解completion以及它的使用吧。
completion结构体
completion结构体定义在头文件<linux/completion.h>中[3],整个头文件才100来行,可以说非常简单了,具体结构为:
1 | struct completion{ |
从结构体中可以看出,completion是基于等待队列来实现的,并且使用FIFO的方式来对线程进行排队。
其中,done成员相当于一个统计量[4],当它:
- 为0时,表示等待队列上还有线程在等待
- 大于0时,表示有多少个线程等待的条件已完成,不需要等待,可以继续执行。
将等待的任务排成列表,swait_queue_head_wait作为头节点,并使用一个自旋锁(raw_spinlock_t)来进行同步操作。
可以在内核编程中,定义一个全局的completion结构体,并等待后续动态初始化。
completion操作函数
初始化
1
2
3
4
5static inline void init_completion(struct completion *x)
{
x->done = 0;
init_swait_queue_head(&x->wait);
}将
x->done设置为0,表示就存在需要等待的线程了。并初始化等待队列。这是一种动态初始化的方式,适用于之前completion没有初始化过的情况。如果之前completion被初始化过,而现在又想继续使用,也可以调用这个函数:
1
2
3
4static inlien void reinit_completion(struct compeltion *x)
{
x->done = 0;
}仅表示现在又有新的线程需要等待。
等待completion事件完成
1
2
3
4
5void __sched wait_for_completion(struct completion *x)
{
wait_for_common(x, MAX_SCHEDULE_TIMEOUT, TASK_UNINTERRUPTIBLE);
}
EXPORT_SYMBOL(wait_for_completion);这只是一种实现方式,没有超时时间,也不会被打断。wait_for_completion_*还有多种实现方式,可以按需求使用。
其中
wait_for_common函数包装了具体的实现过程,包括如下流程:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15static inline long __sched
__wait_for_common(struct completion *x, long (*action)(long), long timeout, int state)
{
might_sleep();
complete_acquire(x);
raw_spin_lock_irq(&x->wait.lock);
timeout = do_wait_for_common(x, action, timeout, state);
raw_spin_unlock_irq(&x->wait.lock);
complete_release(x);
return timeout;
}可以看出,在等待之前加上了自旋锁,然后
do_wait_for_common完成后,释放锁。等待的过程用do-while实现,是一种忙等待,但是对于轻量级的任务还是合适的。标记completion完成
1
2
3
4
5
6
7
8
9
10
11
12void complete(struct completion *x)
{
unsigned long flags;
raw_spin_lock_irqsave(&x->wait.lock, flags);
if (x->done != UINT_MAX)
x->done++;
swake_up_locked(&x->wait);
raw_spin_unlock_irqrestore(&x->wait.lock, flags);
}
EXPORT_SYMBOL(complete);complete函数通常在工作线程任务完成时调用,将x->done自增,使其大于0,标志等待的工作线程已完成,do_wait_for_common也会结束忙等待。同时将当前线程从等待队列中唤醒。或者也可以使用
complete_all方法来通知所有等待这个completion的线程,再更多线程同步的情况下很好用,比mutex之类的方法更方便。
具体实践
在学习相关completion知识之后,我在磁盘模拟器中添加了相关的同步控制,核心代码如下:
1 | struct completion read_event; |
在这个实施中,由于some_event_task是共享变量,在主线程和子线程中都会改变它,所以需要对子线程加以同步控制;同时,在子线程中,由于想要设备按一定的顺序执行请求,故在读写请求中也加上同步以控制其执行顺序。该实施仅提供completion实际使用的一些说明,并不包括全部completion的使用方法。